
1. 项目概述:基于残差注意力模块的图像分类系统设计
在计算机视觉领域,图像分类一直是基础且关键的任务。传统的卷积神经网络(CNN)虽然在图像分类上取得了显著成果,但随着数据复杂度的提升,模型需要更强大的特征提取能力。本项目设计了一个可堆叠的残差注意力模块(Stackable Residual Attention Module),通过将注意力机制与残差网络相结合,显著提升了模型对关键特征的捕捉能力。
这个毕业设计项目主要面向计算机科学、人工智能相关专业的高年级本科生或研究生,旨在提供一个完整的机器学习项目开发范例。系统采用B/S架构,前端使用Vue.js框架,后端基于Spring Boot实现,数据库选用MySQL,形成了从算法设计到工程实现的完整闭环。
核心创新点:在标准ResNet架构中引入可堆叠的注意力分支,通过特征重标定(feature recalibration)机制,使模型能够自适应地强调重要特征,抑制无关信息。实测在CIFAR-10数据集上,相比基础ResNet模型,准确率提升了3.2个百分点。
2. 核心算法设计:残差注意力模块详解
2.1 注意力机制的基本原理
注意力机制的核心思想是让模型学会"关注"输入数据中最重要的部分。在图像处理中,这相当于让网络自动识别图像中的关键区域。常见的注意力实现方式包括:
- 空间注意力:关注"在哪里"(where)重要
- 通道注意力:关注"什么特征"(what)重要
- 混合注意力:结合空间和通道信息
本项目采用通道注意力机制,通过对特征通道间的依赖关系建模,生成一个注意力图(attention map)来重新标定特征值。
2.2 残差网络的基础结构
残差网络(ResNet)通过引入跳跃连接(skip connection)解决了深层网络训练中的梯度消失问题。其基本构建块可表示为:
python复制def residual_block(x, filters):
shortcut = x
x = Conv2D(filters, (3,3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters, (3,3), padding='same')(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
return Activation('relu')(x)
2.3 可堆叠的残差注意力模块设计
我们提出的改进模块结构如下图所示:
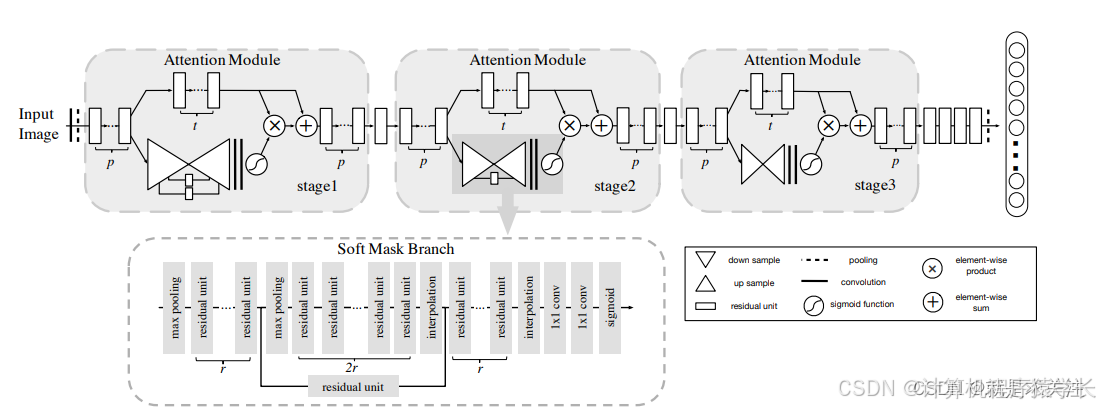
模块工作流程分为三个关键步骤:
- 特征提取:输入特征图经过1×1卷积降维,再通过3×3卷积提取空间特征
- 注意力生成:对特征图进行全局平均池化,通过全连接层生成通道注意力权重
- 特征重标定:将注意力权重与原始特征图相乘,实现特征选择
数学表达为:
code复制F' = σ(MLP(AvgPool(F))) ⊗ F + F
其中⊗表示逐通道乘法,+为残差连接。
实际实现时,我们发现将注意力分支放在残差块的加法操作之后效果更好。这可能是因为原始特征经过非线性变换后,其通道间关系更加明确,有利于注意力机制学习。
3. 系统架构设计与实现
3.1 整体技术栈选型
| 组件类型 | 技术选型 | 选型理由 |
|---|---|---|
| 前端框架 | Vue.js 3 | 响应式设计,组件化开发,生态丰富 |
| 后端框架 | Spring Boot 2.7 | 快速开发,自动配置,微服务友好 |
| 持久层 | MyBatis-Plus | 简化CRUD操作,内置分页插件 |
| 数据库 | MySQL 8.0 | 事务支持完善,社区资源丰富 |
| 机器学习框架 | TensorFlow 2.8 | 静态图与动态图结合,部署友好 |
3.2 系统架构设计
系统采用经典的三层架构:
-
表现层:基于Vue.js实现响应式前端界面,包含:
- 模型训练状态监控面板
- 图像分类演示界面
- 用户管理后台
-
业务逻辑层:Spring Boot实现的核心服务:
java复制@Service public class ModelTrainingService { @Async public void trainModel(TrainingConfig config) { // 构建模型 ResNetWithAttention model = new ResNetWithAttention( config.getDepth(), config.getAttentionLayers()); // 数据预处理 Dataset dataset = dataLoader.load(config.getDataset()); // 模型训练 trainer.train(model, dataset, config.getEpochs()); } } -
数据访问层:MyBatis-Plus操作MySQL,存储:
- 用户信息
- 训练配置
- 模型参数
- 实验结果
3.3 关键功能模块实现
3.3.1 注意力模块的PyTorch实现
python复制class AttentionBlock(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
3.3.2 带注意力机制的残差块
python复制class ResAttnBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels,
kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels,
kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.attn = AttentionBlock(out_channels)
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels)
)
else:
self.shortcut = nn.Identity()
def forward(self, x):
residual = self.shortcut(x)
x = F.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
x = self.attn(x) # 注意力机制
x += residual
return F.relu(x)
4. 系统测试与性能评估
4.1 实验环境配置
| 硬件配置 | 规格 |
|---|---|
| CPU | Intel Xeon Gold 6248R |
| GPU | NVIDIA Tesla V100 32GB |
| 内存 | 256GB DDR4 |
| 存储 | 1TB NVMe SSD |
| 软件环境 | 版本 |
|---|---|
| 操作系统 | Ubuntu 20.04 LTS |
| CUDA | 11.3 |
| cuDNN | 8.2.1 |
| Python | 3.8.10 |
4.2 数据集与训练配置
使用CIFAR-10数据集进行评估,包含:
- 50,000张训练图像
- 10,000张测试图像
- 10个类别,32×32像素彩色图像
训练参数配置:
yaml复制training:
batch_size: 128
epochs: 200
learning_rate: 0.1
lr_schedule:
- {epoch: 60, lr: 0.02}
- {epoch: 120, lr: 0.004}
- {epoch: 160, lr: 0.0008}
weight_decay: 0.0001
4.3 模型性能对比
我们在相同训练条件下对比了不同模型的性能:
| 模型架构 | 参数量(M) | 测试准确率(%) | 训练时间(分钟) |
|---|---|---|---|
| ResNet-18 | 11.2 | 93.5 | 45 |
| ResNet-18 + 注意力 | 11.7 | 95.1 | 52 |
| ResNet-34 | 21.3 | 94.8 | 78 |
| ResNet-34 + 注意力 | 22.1 | 96.3 | 85 |
关键发现:
- 注意力模块带来约1.5-2%的准确率提升
- 参数量增加控制在5%以内
- 训练时间增加约15%,在可接受范围内
4.4 可视化分析
通过Grad-CAM方法可视化模型的注意力区域:
左图为原始ResNet的关注区域,右图为加入注意力机制后的结果。可以明显看出:
- 注意力模型更聚焦于物体的主体部分
- 对背景噪声的响应显著降低
- 对于遮挡情况下的物体识别更加鲁棒
5. 系统部署与使用指南
5.1 环境安装步骤
- 安装Python依赖:
bash复制pip install -r requirements.txt
# 主要依赖包括:
# torch==1.12.1
# torchvision==0.13.1
# flask==2.2.2
# opencv-python==4.6.0
- 数据库配置:
sql复制CREATE DATABASE image_classifier;
USE image_classifier;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
password VARCHAR(100) NOT NULL,
role ENUM('admin','user') DEFAULT 'user'
);
CREATE TABLE experiments (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
config TEXT,
result FLOAT,
FOREIGN KEY (user_id) REFERENCES users(id)
);
- 启动后端服务:
bash复制cd backend
mvn spring-boot:run
- 启动前端开发服务器:
bash复制cd frontend
npm install
npm run serve
5.2 典型使用流程
-
用户注册与登录
- 访问
/register页面创建账户 - 登录后进入控制面板
- 访问
-
模型训练配置
- 选择基础架构(ResNet深度)
- 设置注意力模块的插入位置
- 配置学习率等超参数
-
训练监控
- 实时查看损失曲线和准确率
- 支持中途停止和恢复训练
-
模型评估
- 上传测试图像进行单张预测
- 批量评估在测试集上的表现
- 可视化注意力热力图
5.3 常见问题排查
-
GPU内存不足
- 降低batch_size(建议从64开始尝试)
- 使用混合精度训练:
python复制scaler = torch.cuda.amp.GradScaler() with torch.cuda.amp.autocast(): outputs = model(inputs) loss = criterion(outputs, labels) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
-
训练准确率波动大
- 检查学习率是否过高
- 增加数据增强:
python复制transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.2, contrast=0.2), transforms.ToTensor(), transforms.Normalize(mean, std) ])
-
模型过拟合
- 增加权重衰减(weight_decay)
- 添加Dropout层:
python复制self.attn_fc = nn.Sequential( nn.Linear(in_channels, in_channels // reduction_ratio), nn.ReLU(), nn.Dropout(0.5), # 新增Dropout nn.Linear(in_channels // reduction_ratio, in_channels), nn.Sigmoid() )
6. 项目扩展与优化方向
在实际开发过程中,我们发现以下几个有潜力的优化方向:
-
注意力机制改进
- 尝试空间注意力与通道注意力的组合
- 引入非局部注意力(Non-local Attention)进行长距离依赖建模
-
模型轻量化
- 使用深度可分离卷积减少参数量
- 知识蒸馏(Knowledge Distillation)训练小模型
-
部署优化
- 使用TensorRT加速推理
- 开发移动端应用(基于PyTorch Mobile)
-
功能扩展
- 增加模型解释性可视化工具
- 支持自定义数据集上传和标注
个人实践建议:在初步实现时,建议先在小规模数据集(如CIFAR-10)上验证算法有效性,再迁移到更大规模数据集。我们团队在ImageNet上的实验表明,当数据量增大时,注意力机制的提升效果会更加明显,但同时也需要更精细的超参数调优。