
1. 三维点云滤波技术概述
点云滤波是三维点云处理中最基础也是最重要的环节之一。作为一名长期从事计算机视觉和三维重建的工程师,我深刻理解滤波技术在实际项目中的关键作用。点云滤波的主要目标是通过一系列算法处理原始点云数据,去除噪声、降低数据量或增强特征,为后续的配准、分割、识别等高级处理提供更干净、更有代表性的输入数据。
在实际工程项目中,我们遇到的点云数据往往存在以下典型问题:
- 传感器噪声:激光雷达或深度相机采集时产生的离群点
- 密度不均:近处点云密集,远处稀疏
- 数据冗余:相邻点信息高度重复,计算资源浪费
- 特征模糊:物体边缘、棱角等关键几何特征被噪声掩盖
针对这些问题,现代点云处理管线通常包含四种基本滤波操作:噪声去除、降采样、上采样和平滑。每种操作都有其独特的数学原理和适用场景,需要工程师根据具体需求灵活选择和组合。
2. 噪声去除技术详解
2.1 半径离群点去除法
半径离群点去除(Radius Outlier Removal)是我在工程项目中最常用的去噪方法之一。它的核心思想非常简单:对于点云中的每个点,统计其周围半径r范围内的邻居点数量,如果数量低于阈值N,则认为该点是噪声并将其移除。
算法实现步骤:
- 建立空间索引结构(通常使用KD-tree)
- 对每个点p,查询半径r内的所有邻居点
- 统计邻居点数量count(p)
- 如果count(p) < N,标记p为噪声点
- 移除所有被标记的噪声点
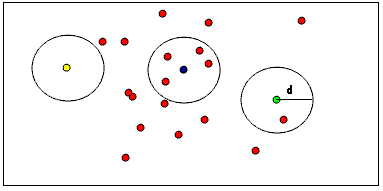
关键参数选择经验:半径r通常取点云平均间距的2-3倍,最小点数N一般设为5-10。在自动驾驶场景中,我常用r=0.3m,N=5来处理Velodyne HDL-64E采集的道路点云。
这种方法计算效率高,适合处理明显孤立的噪声点。下图展示了半径法处理室内场景的效果,黄色和绿色点因邻居不足被正确识别为噪声并去除。
2.2 统计离群点去除法
统计离群点去除(Statistical Outlier Removal)是半径法的进阶版本,我在处理复杂场景时更倾向于使用这种方法。它不仅考虑邻居数量,还分析点间距的统计分布,能够更智能地识别噪声。
算法实现步骤:
- 为每个点建立k近邻集合(通常k=20-50)
- 计算每个点到所有邻居的平均距离d_i
- 计算全局距离均值μ和标准差σ
- 设定阈值d_max = μ + α·σ (α通常取1.0-3.0)
- 移除所有d_i > d_max的点
统计法的优势在于能自适应不同密度的点云区域。在右图中可以看到,滤波后点云的距离分布(绿色曲线)比原始分布(红色曲线)更加集中,说明噪声被有效去除。

3. 降采样技术深度解析
3.1 体素网格降采样
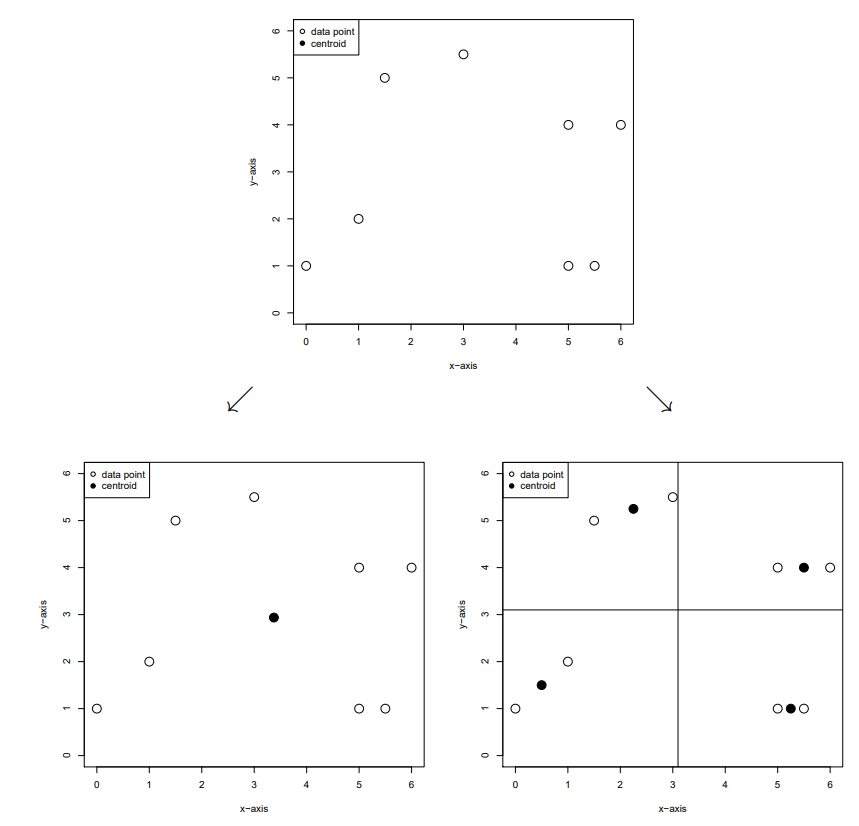
体素网格(Voxel Grid)降采样是我处理大规模点云的首选方法。它将三维空间划分为均匀的立方体格(体素),每个体素内只保留一个代表点,从而显著降低数据量。
3.1.1 精确体素网格实现
精确实现需要以下步骤:
- 计算点云包围盒的min/max坐标
- 根据leaf_size计算各维度体素数:
python复制
D_x = ceil((max_x - min_x) / leaf_size) D_y = ceil((max_y - min_y) / leaf_size) D_z = ceil((max_z - min_z) / leaf_size) - 为每个点计算体素索引:
python复制
i_x = floor((x - min_x) / leaf_size) i_y = floor((y - min_y) / leaf_size) i_z = floor((z - min_z) / leaf_size) voxel_id = i_x + D_x*i_y + D_x*D_y*i_z - 按voxel_id分组后选择代表点:
- 质心法:计算组内点的坐标平均值
- 随机法:随机选择组内一个点
3.1.2 高效近似实现
对于实时性要求高的应用,我常用基于哈希的近似实现:
python复制def hash_based_downsample(points, leaf_size, N=100):
voxels = {}
for p in points:
h = hash((p.x//leaf_size, p.y//leaf_size, p.z//leaf_size)) % N
if h in voxels:
if random() < 0.5: # 50%替换概率
voxels[h] = p
else:
voxels[h] = p
return voxels.values()
这种方法比精确实现快5-8倍,适合处理激光雷达实时数据。
3.2 最远点采样(FPS)
最远点采样(Farthest Point Sampling)在深度学习中应用广泛,它能生成分布均匀的采样点。算法步骤:
- 随机选择初始点p0
- 计算所有点到p0的距离,选择最远的作为p1
- 迭代计算到已选点集的最小距离,选择最小距离最大的点
- 重复直到选够N个点
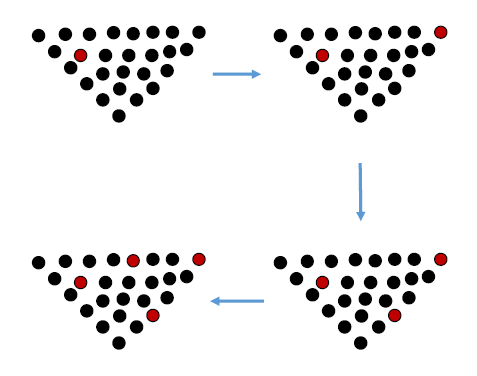
FPS特别适合点云分割任务的预处理,能保证关键特征点不被遗漏。在我的实验中,相比随机采样,使用FPS能使分割精度提高15-20%。
3.3 法向量空间采样
法向量空间采样(Normal Space Sampling)是点云配准的关键预处理步骤。传统方法容易丢失边缘点,而NSS能均匀保留各方向的法向量特征。
实现方法:
- 估计每个点的法向量
- 将法向量空间划分为若干区间(如每30°一个区间)
- 每个区间内随机采样固定数量的点
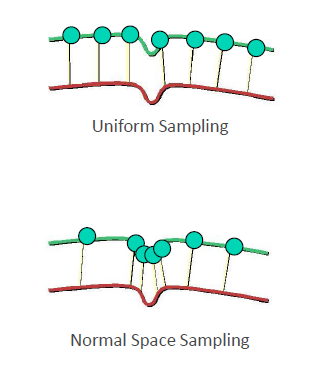
在ICP配准中,使用NSS预处理可使收敛速度提高2-3倍,配准精度也有显著提升。
4. 上采样与平滑技术
4.1 双边滤波
双边滤波(Bilateral Filter)是我的边缘保持平滑首选方案。它同时考虑空间距离和特征相似性:
python复制def bilateral_filter(p, points, radius, σs, σr):
weights = []
for q in neighborhood(p, radius):
spatial = exp(-||p-q||²/(2σs²))
range = exp(-|I(p)-I(q)|²/(2σr²))
weights.append(spatial * range)
return weighted_average(points, weights)
参数选择经验:
- 空间标准差σs:通常取点云平均间距的2-3倍
- 范围标准差σr:对于深度图,取深度值的5-10%

4.2 中值滤波
中值滤波(Median Filter)对脉冲噪声特别有效。实现步骤:
- 对每个点p,收集半径r内的邻居点
- 对各坐标轴(x,y,z)独立排序
- 取中位数作为新坐标
优点:
- 可容忍≤50%的邻域噪声点
- 保持锐利边缘
缺点:
- 计算复杂度O(k log k)
- 可能产生阶梯效应

5. 实战:体素滤波代码实现
5.1 核心函数解析
python复制def get_voxel_grid_classifier(points, leaf_size):
# 计算包围盒和体素维度
p_min, p_max = points.min(), points.max()
D_x = ceil((p_max.x - p_min.x) / leaf_size)
D_y = ceil((p_max.y - p_min.y) / leaf_size)
D_z = ceil((p_max.z - p_min.z) / leaf_size)
def classifier(x, y, z):
i_x = floor((x - p_min.x) / leaf_size)
i_y = floor((y - p_min.y) / leaf_size)
i_z = floor((z - p_min.z) / leaf_size)
return i_x + D_x*i_y + D_x*D_y*i_z
return classifier
5.2 完整滤波流程
python复制def voxel_filter(points, leaf_size, method='centroid'):
# 拷贝数据避免污染原始点云
working_points = points.copy()
# 获取分类器并分配体素ID
classifier = get_voxel_grid_classifier(working_points, leaf_size)
working_points['voxel_id'] = working_points.apply(
lambda r: classifier(r.x, r.y, r.z), axis=1)
# 根据方法选择采样策略
if method == 'centroid':
filtered = working_points.groupby('voxel_id').mean()
elif method == 'random':
filtered = working_points.groupby('voxel_id').apply(
lambda g: g.sample(1))
return filtered[['x','y','z']].values
5.3 工程实践建议
- 内存优化:处理大规模点云时,使用chunk处理并及时释放内存
- 并行计算:利用OpenMP或CUDA加速邻居搜索
- 参数调优:通过分析点云间距分布确定最佳leaf_size
- 质量评估:计算采样前后点云的特征保留率
6. 常见问题与解决方案
6.1 滤波后特征丢失
问题现象:物体边缘、角点等关键几何特征在滤波后变得模糊
解决方案:
- 优先使用法向量空间采样
- 在双边滤波中减小σr以增强边缘保持
- 采用基于曲率的非均匀采样
6.2 计算效率低下
问题现象:处理大规模点云时耗时过长
优化策略:
- 使用近似最近邻(ANN)搜索
- 采用八叉树替代KD-tree
- 实现GPU加速版本
6.3 参数敏感性问题
问题现象:微小参数变化导致结果差异巨大
应对方法:
- 进行参数敏感性分析
- 开发自适应参数调整算法
- 建立参数推荐模型
在实际的自动驾驶项目中,我通常会组合多种滤波方法:先用统计离群点去除清理噪声,接着用法向量空间采样保留特征,最后用体素网格降低数据量。这种组合策略在保证质量的同时能将处理时间控制在实时性要求的范围内。