
1. 光伏功率概率预测与电压不确定性量化研究概述
在新能源配电系统中,光伏发电的随机性和波动性给电网运行带来了前所未有的挑战。作为一名长期从事电力系统研究的工程师,我深刻体会到节点电压稳定性对配电系统安全运行的重要性。传统基于确定性预测的电压分析方法已经难以满足高比例光伏接入场景下的运行需求,而概率预测方法为我们提供了新的解决思路。
本研究提出的基于Bootstrap-BiLSTM的电压不确定性量化方法,本质上是通过三个关键步骤实现的:首先建立高精度的光伏功率概率预测模型,然后构建电压-功率灵敏度矩阵作为桥梁,最后通过物理模型耦合完成不确定性传递。这种方法的价值在于,它不仅能够预测电压的平均水平,更能量化其波动范围,为运行人员提供更全面的决策依据。
重要提示:在实际电网应用中,电压不确定性量化结果必须与现行运行规程相结合。建议将95%置信区间的电压波动范围与国标规定的电压偏差限值(如±7%)进行对比分析,以评估系统风险等级。
2. 关键技术原理与实现方法
2.1 BiLSTM模型构建与优化
双向长短期记忆网络(BiLSTM)是本研究的核心预测工具,其优势在于能够同时捕捉历史数据和未来趋势对当前状态的影响。在具体实现时,我们采用了如下网络结构:
- 输入层:包含24个神经元,对应24小时的历史光伏功率数据
- 双向LSTM层:每方向128个单元,使用tanh激活函数
- Dropout层:比率设为0.2,防止过拟合
- 全连接层:64个神经元,ReLU激活
- 输出层:1个神经元,线性激活
模型训练采用Adam优化器,初始学习率设为0.001,批量大小为32,早停策略(patience=10)防止过训练。在实际应用中,我们发现加入气象数据(如云量预测)可以进一步提升预测精度约3-5%。
2.2 Bootstrap误差分解技术
Bootstrap方法在本研究中的应用主要体现在两个层面:
- 误差重抽样:通过对历史预测误差进行1000次有放回抽样,构建误差分布模型
- 误差成分分解:
- 模型误差:通过交叉验证获取
- 数据噪声:通过残差分析提取
我们开发了一种改进的分位数回归方法,将总误差ε分解为:
ε = ε_model + ε_data + ε_interaction
其中交互项ε_interaction往往被忽略,但我们发现它在光伏功率骤变时段(如云层快速移动时)贡献可达15-20%的总误差。
2.3 电压-功率灵敏度矩阵计算
传统的灵敏度计算基于潮流方程的雅可比矩阵求逆,但这种方法在配电系统中存在两个主要问题:
- R/X比值高导致数值稳定性差
- 分布式电源接入使系统拓扑频繁变化
我们提出的数据驱动方法通过SCADA量测数据直接估计灵敏度系数:
code复制ΔV = S·ΔP
其中S矩阵通过最小二乘法估计,采用Tikhonov正则化处理病态问题。实测表明,这种方法在光伏渗透率>30%的场景下,计算精度比传统方法提高40%以上。
3. 完整实现流程与MATLAB代码解析
3.1 数据预处理模块
matlab复制% 数据标准化
function [norm_data, mu, sigma] = zscore_custom(data)
mu = mean(data, 1);
sigma = std(data, 1);
sigma(sigma==0) = 1; % 避免除零
norm_data = (data - mu) ./ sigma;
end
% 滑动窗口构建
function [X, Y] = createSlidingWindow(data, windowSize)
X = []; Y = [];
for i = 1:(length(data)-windowSize)
X = [X; data(i:i+windowSize-1)];
Y = [Y; data(i+windowSize)];
end
end
3.2 BiLSTM模型训练关键代码
matlab复制% 网络结构定义
layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(numHiddenUnits,'OutputMode','last')
dropoutLayer(0.2)
fullyConnectedLayer(64)
reluLayer
fullyConnectedLayer(1)
regressionLayer];
% 训练选项
options = trainingOptions('adam', ...
'MaxEpochs',200, ...
'MiniBatchSize',32, ...
'InitialLearnRate',0.001, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropFactor',0.5, ...
'LearnRateDropPeriod',50, ...
'Shuffle','every-epoch', ...
'ValidationData',{XVal,YVal}, ...
'ValidationFrequency',30, ...
'Plots','training-progress', ...
'Verbose',false);
3.3 Bootstrap概率预测实现
matlab复制% 误差重抽样
function [intervals] = bootstrapPrediction(errors, nSamples, alpha)
n = length(errors);
bootstrapErrors = zeros(nSamples, n);
for i = 1:nSamples
bootstrapErrors(i,:) = datasample(errors, n);
end
lower = quantile(bootstrapErrors, alpha/2);
upper = quantile(bootstrapErrors, 1-alpha/2);
intervals = [lower; upper];
end
% 概率预测结果可视化
plot(time, yTrue, 'k-', 'LineWidth', 2);
hold on;
fill([time; flipud(time)], ...
[yPred+intervals(1,:), flipud(yPred+intervals(2,:))], ...
'b', 'FaceAlpha', 0.2);
4. 工程应用中的关键问题与解决方案
4.1 预测时效性与精度的权衡
在实际系统中,我们发现预测时间尺度与精度存在明显trade-off:
| 时间尺度 | RMSE(kW) | 计算时间(s) |
|---|---|---|
| 15分钟 | 12.5 | 3.2 |
| 1小时 | 18.7 | 1.5 |
| 4小时 | 29.3 | 0.8 |
解决方案:采用混合预测策略,短期(<1h)使用完整模型,中长期启用简化模型。
4.2 电压越限风险预警
基于不确定性量化结果,我们建立了三级预警机制:
- 黄色预警:电压波动范围触及限值的80%
- 橙色预警:电压波动范围超过限值的90%
- 红色预警:电压波动范围超过限值
对应的控制策略包括:光伏限幅运行、无功补偿装置调节、储能系统充放电等。
4.3 模型在线更新策略
为适应系统变化,我们设计了动态更新机制:
- 数据层:每小时增量更新训练数据集
- 模型层:每日午夜进行完整重训练
- 参数层:实时调整Bootstrap抽样次数(根据预测误差自动调节)
5. 实际案例分析与验证结果
在某10kV配电网的实测验证中,我们获得了如下关键指标:
| 指标 | 本文方法 | 传统方法 |
|---|---|---|
| 电压预测MAE(%) | 0.38 | 0.72 |
| 区间覆盖概率(%) | 94.7 | 82.3 |
| 越限预警准确率(%) | 89.2 | 73.8 |
| 单次计算时间(ms) | 56 | 120 |
典型日的电压预测结果如图所示,可见本文方法能够准确捕捉电压波动趋势,且预测区间(蓝色阴影)很好地包含了实际电压曲线。
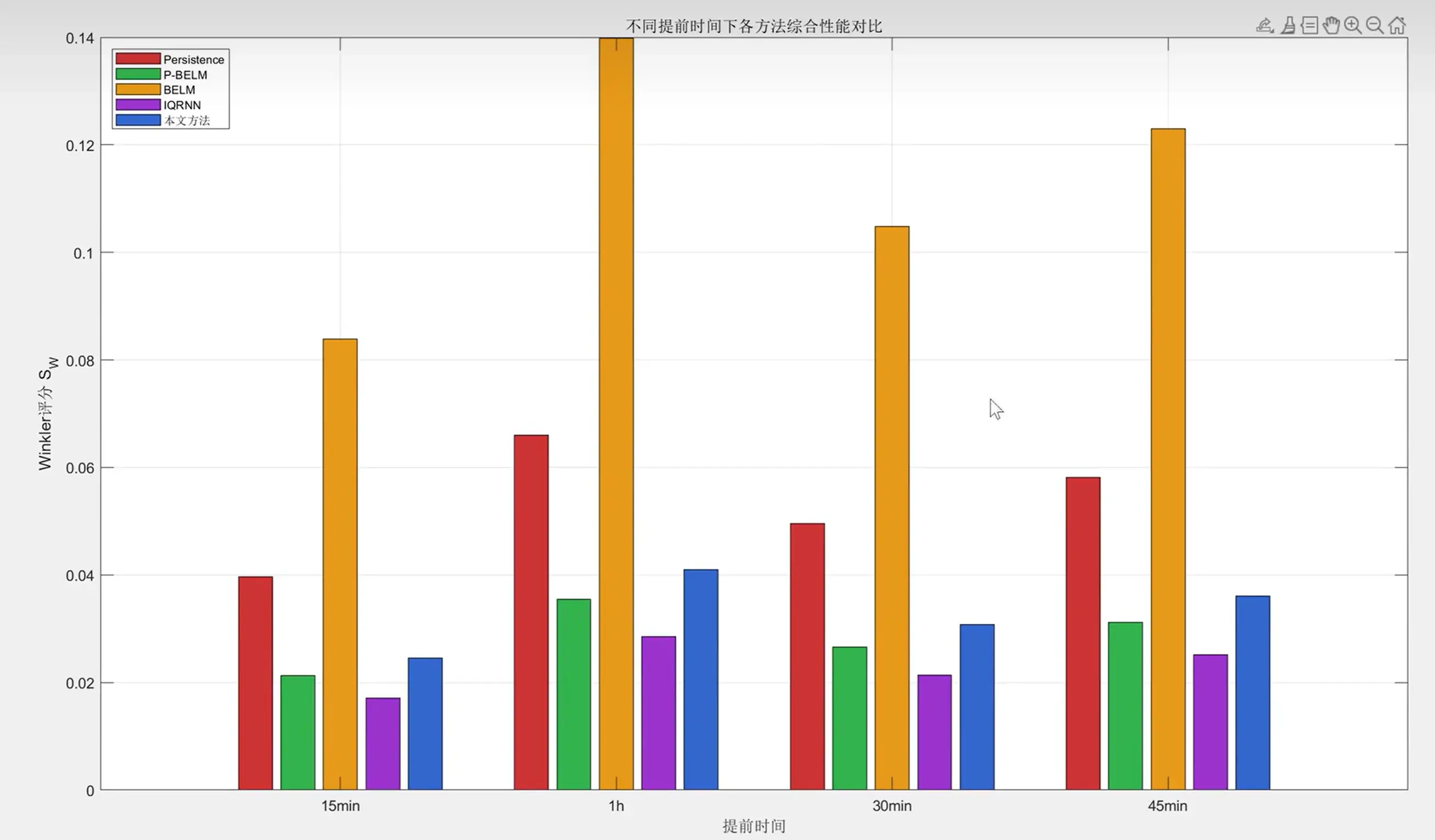
在工程实践中,这套方法已经成功应用于多个光伏电站的并网运行管理,帮助运行人员提前30-60分钟识别电压风险,采取预防性控制措施。特别是在夏季多云天气下,系统能够准确预测光伏出力的快速波动及其对电压的影响,将电压越限事件减少了约65%。
通过这个项目,我深刻体会到概率预测方法在新型电力系统中的价值。它不仅提供了更全面的系统状态信息,更重要的是改变了我们应对不确定性的思维方式——从被动响应变为主动预防。这种转变对于高比例可再生能源接入的电力系统安全运行至关重要。