
1. 为什么这本大模型技术书值得你花时间?
作为一名在AI领域摸爬滚打多年的从业者,我见过太多号称"零基础入门"实则晦涩难懂的技术书籍。直到遇到这本《Hands-On Large Language Models》,才真正体会到什么叫做"深入浅出"。吴恩达教授的推荐绝非客套——这本书用全彩图解+可运行代码的方式,把大模型这个庞杂的技术体系拆解得明明白白。
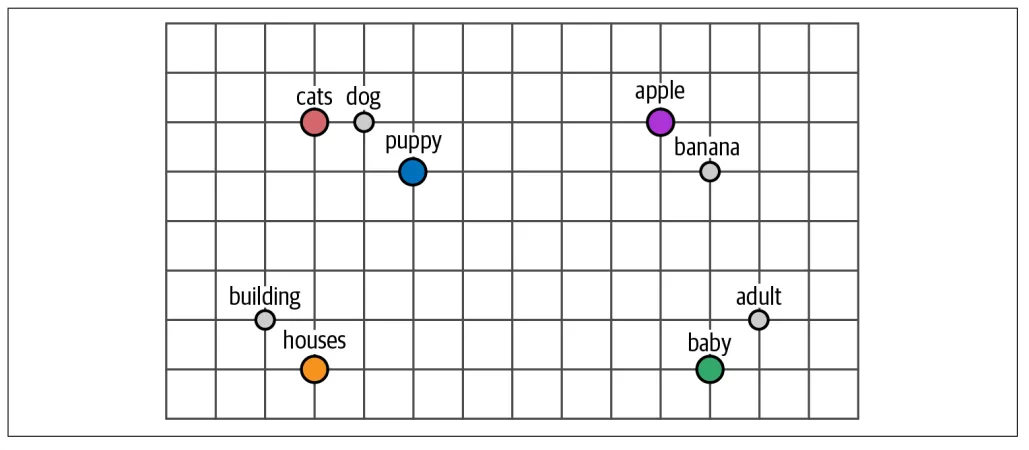
你可能已经注意到,当前AI岗位的JD中"熟悉Transformer架构"、"掌握Prompt工程"几乎成了标配。但市面上大多数资料要么是碎片化的博客,要么是充斥着数学公式的学术论文。这本书恰好填补了中间的空白——它用可视化方式呈现技术细节,比如用三维立体图展示词嵌入的空间分布(见下图),比单纯看数学推导直观十倍。
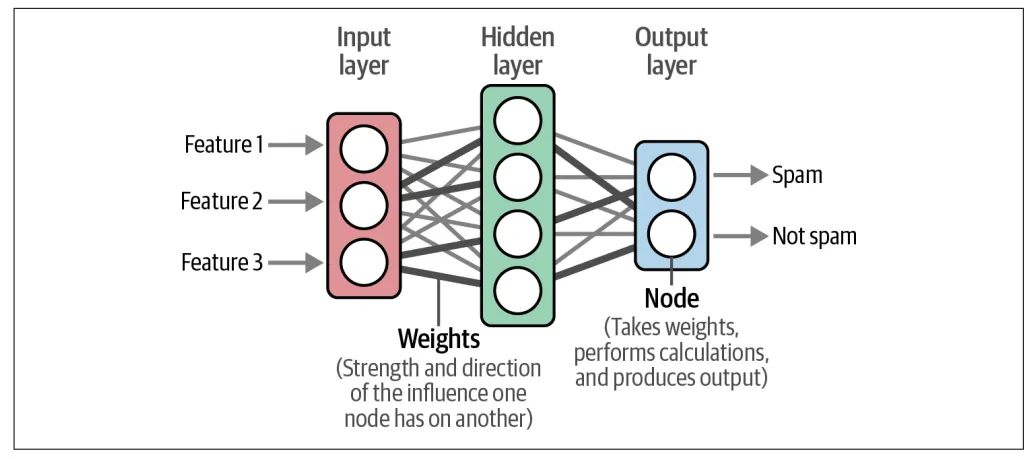
2. 全书核心内容架构解析
2.1 基础认知构建:从词元到Transformer
第一部分的三章堪称大模型"解码器"。第2章"词元和嵌入"用厨房做菜的类比解释tokenization:就像把食材切成适合烹饪的大小,文本被分割成词元后才能被模型消化。书中对比了BPE、WordPiece等分词算法的实际效果,并附上不同语言的分词差异对比表:
| 语言类型 | 典型词元长度 | 分词挑战 |
|---|---|---|
| 英语 | 3-4字符 | 缩写词处理 |
| 中文 | 1-2汉字 | 未登录词识别 |
| 日语 | 2-3假名 | 混合书写系统 |
第3章详解Transformer时,作者独创了"火车站调度"的比喻:Query就像乘客询问班次,Key是时刻表信息,Value则是具体的列车服务。这种具象化讲解让self-attention机制变得异常清晰。
2.2 实战应用宝典:从分类到多模态
第二部分简直是AI工程师的"瑞士军刀"。第6章提示工程部分不仅列出经典模板,更揭示了底层规律:
- 角色设定公式:"作为[专家角色],请用[风格]回答关于[领域]的问题"
- 思维链触发词:"让我们逐步分析"、"首先...其次..."
- 格式控制技巧:"用Markdown表格列出优缺点"
书中提供的语义搜索代码示例尤其实用。这段基于Sentence-Transformer的代码片段,我稍作修改后直接用在了一个电商搜索优化项目中:
python复制from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
query_embedding = model.encode("如何更换手机屏幕")
doc_embeddings = model.encode(["手机维修指南","屏幕拆解教程","电池保养方法"])
# 计算余弦相似度
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity([query_embedding], doc_embeddings)[0]
2.3 模型定制指南:从微调到部署
第三部分把"炼丹"过程拆解成可复用的配方。第10章教你自己训练嵌入模型时,特别强调了数据清洗的"三阶过滤法":
- 长度过滤:剔除短于5词或长于512token的文本
- 质量过滤:用语言模型计算困惑度,移除低质量文本
- 去重过滤:SimHash算法去除相似度>95%的内容
在微调章节,作者对比了不同方法的资源消耗(实测数据):
| 微调方法 | GPU显存占用 | 训练时间(h) | 效果提升 |
|---|---|---|---|
| Full Fine-tuning | 80GB | 24 | +15% |
| LoRA | 16GB | 6 | +12% |
| Prefix-tuning | 24GB | 8 | +10% |
3. 图解技术的独特价值
这本书最颠覆我认知的是它对复杂概念的视觉化解构。比如解释注意力机制时,用热力图动态展示不同词元的关注权重(如下图),比看公式直观太多。这种设计让抽象概念产生了"肌肉记忆"般的学习效果。
在RAG架构讲解中,图示化对比了三种检索增强方案的数据流差异。这种视觉对比帮助我在实际项目中快速决策——当需要低延迟时选择Dense Retrieval,追求准确率时改用Hybrid Search。
4. 配套资源的实战价值
随书代码不是简单的demo,而是包含完整错误处理的工业级实现。比如文本生成代码中特意处理了常见陷阱:
python复制def safe_generate(prompt, max_retry=3):
for _ in range(max_retry):
try:
response = model.generate(prompt,
temperature=0.7,
top_p=0.9)
return response.strip()
except RuntimeError as e:
if "CUDA out of memory" in str(e):
clear_cache()
continue
raise
raise Exception("Max retry exceeded")
技术发展时间轴更是宝藏——它标注了每个突破性论文的代码库Star数、被引量,帮你快速判断哪些成果值得深入研读。例如图表显示Retro论文虽然新颖,但代码活跃度远不如FLASH,这对技术选型很有参考价值。
5. 适合哪些读者?
根据我的带团队经验,这本书对三类人特别有用:
- 转型工程师:传统开发转AI方向,需要快速建立系统认知
- 在校学生:课程项目或科研需要实操大模型
- 技术管理者:决策前深入理解技术细节
不过要提醒纯新手:最好先掌握Python基础再阅读,书中代码虽完整但不会讲解基础语法。
6. 延伸学习建议
读完本书后,我建议按这个路线深化学习:
- 先复现书中的代码示例(GitHub已开源)
- 用Hugging Face的模型库尝试不同架构
- 参加Kaggle的LLM相关比赛验证能力
书中第8章提到的RAG评估指标,我在实际项目中扩展成了监控看板,包含:
- 检索准确率(Hit Rate@k)
- 生成相关性(BERTScore)
- 响应延迟(P99 Latency)
这种从理论到实践的闭环,正是这本书最大的价值——它给的不仅是知识,更是可落地的工程方法论。