
1. 论文核心思想与背景解读
这篇论文《Farewell to Item IDs》探讨了推荐系统领域一个根本性的问题:传统基于物品ID(Item ID)的推荐模型在扩展性(scaling)上的局限性。作者团队来自字节跳动,他们发现当模型规模增大时,基于ID的方法性能提升会很快达到瓶颈。这种现象背后的本质原因是ID特征的动态性和不稳定性。
在推荐系统中,每个物品通常会被分配一个唯一的原子ID作为标识符。这种设计虽然简单直接,但存在几个关键缺陷:
- 冷启动问题:新物品的ID从未出现在训练数据中,模型无法立即给出准确推荐
- 知识丢弃问题:下架物品的ID及其关联的用户行为数据会完全失效
- 分布漂移:ID特征的统计分布会随着物品上下架而剧烈波动
作者通过实验观察到:使用ID特征时,模型在训练过程中的embedding分布变化剧烈且不稳定(论文图1左),而使用语义token时分布则平稳得多(图1右)。这种稳定性差异直接影响了大模型的训练效果。
传统推荐系统通常采用两种特征表示:
- 稀疏特征:如用户ID、物品ID等,通过embedding层映射为稠密向量
- 稠密特征:如物品的视觉、文本等多模态内容特征
论文的核心创新点是提出用语义token完全替代传统的原子ID,构建了一个名为TRM(Token-based Recommendation Model)的新框架。这种方法将推荐系统中的物品表示从离散的ID空间转移到连续的语义空间,既保留了物品的个性化特征,又实现了更好的知识共享和迁移能力。
2. TRM框架技术细节解析
2.1 整体架构设计
TRM模型包含三个关键组件,形成了一个完整的处理流水线:
- 协同信号感知的多模态item表示:融合物品内容信息和用户行为信号
- 混合tokenization策略:平衡泛化能力和记忆能力
- 联合优化目标:同时训练判别式和生成式任务
这种设计实现了从原始特征到最终推荐结果的端到端学习,完全摒弃了传统ID特征的使用。下图展示了TRM的整体架构:
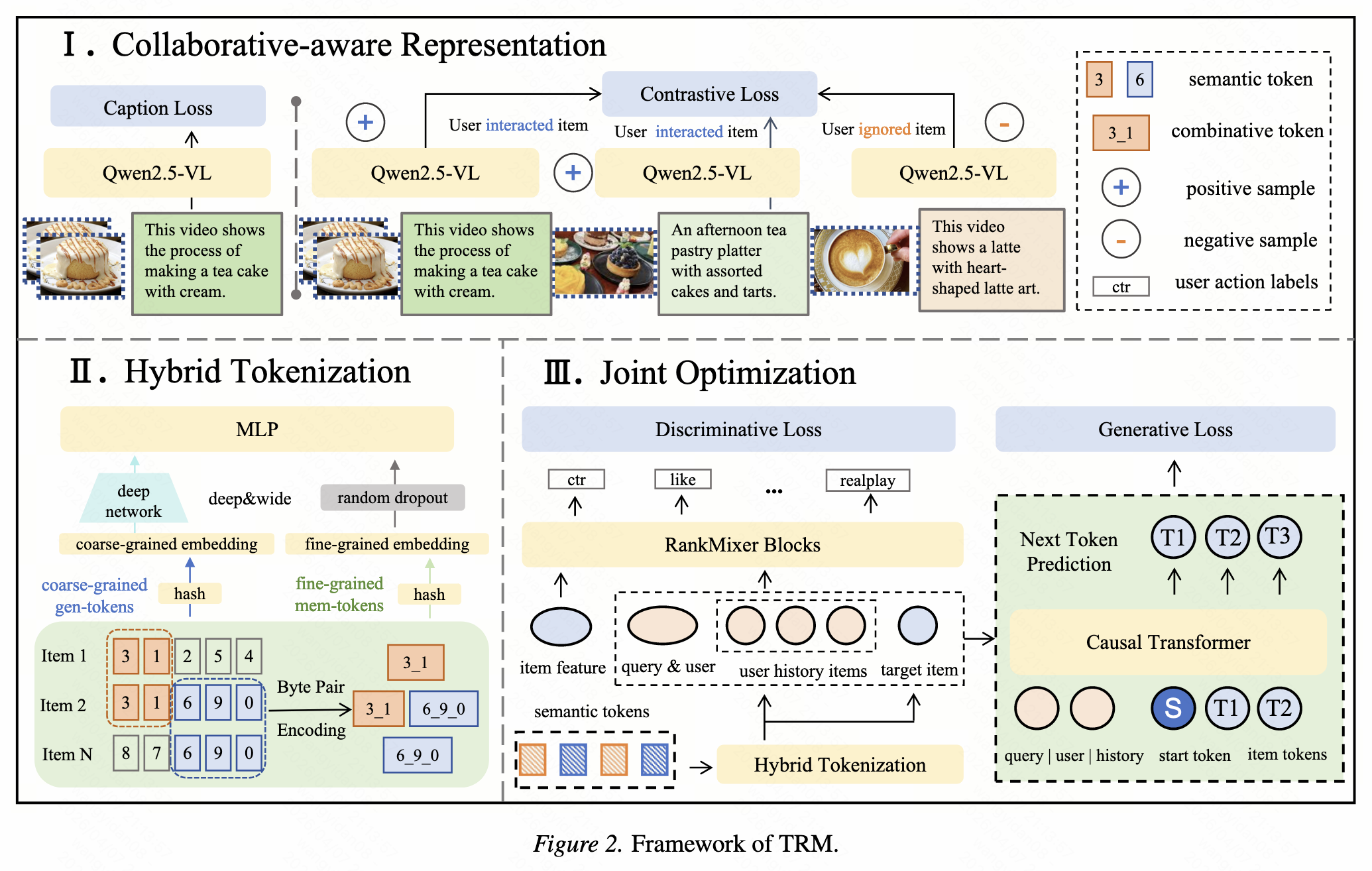
2.2 协同信号感知的多模态表示
第一步的核心目标是让物品的表示既包含其自身的内容信息,又能反映用户行为模式。作者采用了两阶段训练策略:
阶段一:领域自适应预训练
- 输入:视频帧(视觉)、标题/ASR/OCR/描述(文本)
- 模型:多模态大模型(MLLM)
- 任务:视频内容描述生成(自回归)
- 目的:让模型理解短视频领域的特定语义
阶段二:协同信号对齐
- 正样本构造:
- Query-Item对:用户搜索query与点击item
- Item-Item对:频繁共现的item对
- 损失函数:InfoNCE对比损失
code复制L_contrastive = -log[exp(sim(q,i+)/τ)/∑exp(sim(q,i-)/τ)] - 表示提取:MLLM最后一层hidden states的mean pooling
两阶段的联合损失函数为:
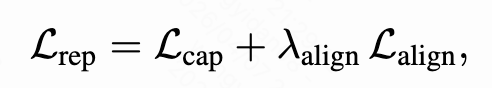
这一步骤的创新点在于将传统的协同过滤信号与深度学习的内容理解相结合,生成的物品embedding同时编码了"是什么"和"被如何交互"的双重信息。
2.3 混合tokenization策略
通过第一阶段获得的物品embedding需要被转化为离散的token序列。直接使用传统的残差量化(RQ)方法会产生以下问题:
- 记忆能力不足:老物品的推荐效果随时间衰减明显
- 组合语义缺失:单个token无法表达复杂的特征组合
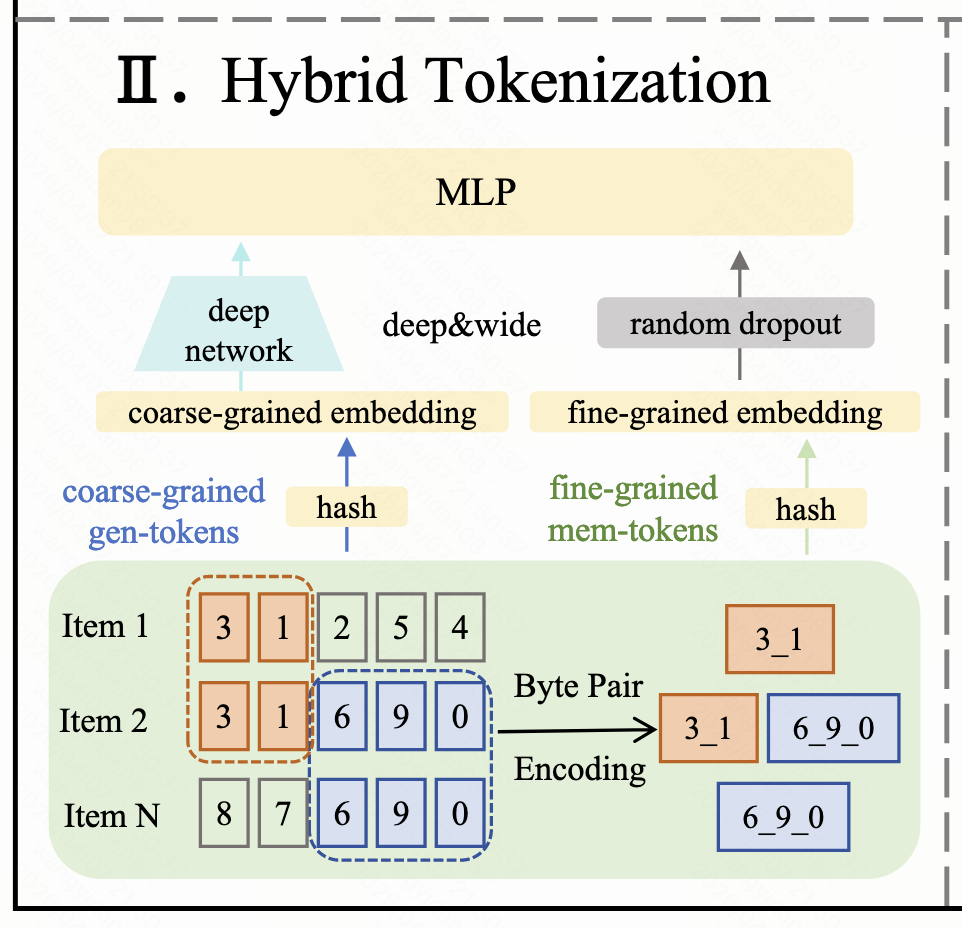
作者的解决方案是设计了一种混合tokenization方法:
- Gen-Tokens:通过RQ-Kmeans生成的基token,负责泛化能力
- Mem-Tokens:通过BPE算法挖掘的高频组合token,负责记忆能力
具体实现流程:
- 对全量物品embedding进行层次聚类,得到基础token词汇表
- 分析token共现模式,使用BPE算法提取有意义的组合模式
- 将gen-token和mem-token的embedding通过Wide&Deep结构融合
这种设计带来了显著的性能提升,如下图所示:
2.4 联合优化目标
为了充分利用语义token的结构化信息,TRM采用了多任务学习框架:
判别目标(主任务):
- 输入:用户特征、历史行为、候选物品特征
- 输出:用户对物品的各种互动概率(点击、点赞等)
- 损失:二元交叉熵(BCE)
code复制L_rank = -[y*log(p)+(1-y)*log(1-p)]
生成目标(辅助任务):
- 输入:用户特征和历史行为
- 输出:目标物品的token序列(自回归生成)
- 损失:负对数似然(NLL)
code复制L_gen = -∑ logP(t_k|t_<k,X)
最终损失为加权求和:
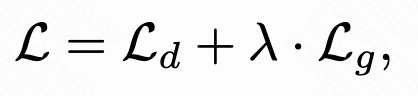
这种联合训练方式使模型既能完成精准的排序任务,又能学习物品token序列的生成规律,增强了模型的语义理解能力。
3. 实验分析与实践启示
3.1 实验设置
数据集:TikTok视频搜索日志
- 规模:数十亿级用户行为
- 特征:多模态视频内容+丰富用户交互信号
基线模型:
- ID-based:DCN、DHEN、WuKong、RankMixer
- Token-based:TIGER、OneRec、SemID
评估指标:
- AUC:整体排序质量
- QAUC:查询粒度的排序质量
- 推理延迟:线上服务性能
3.2 核心实验结果
-
性能对比:
- TRM在减少32.6%稀疏参数的同时,AUC提升0.54%
- 其他token方法均不如ID-based模型,验证了TRM设计的必要性
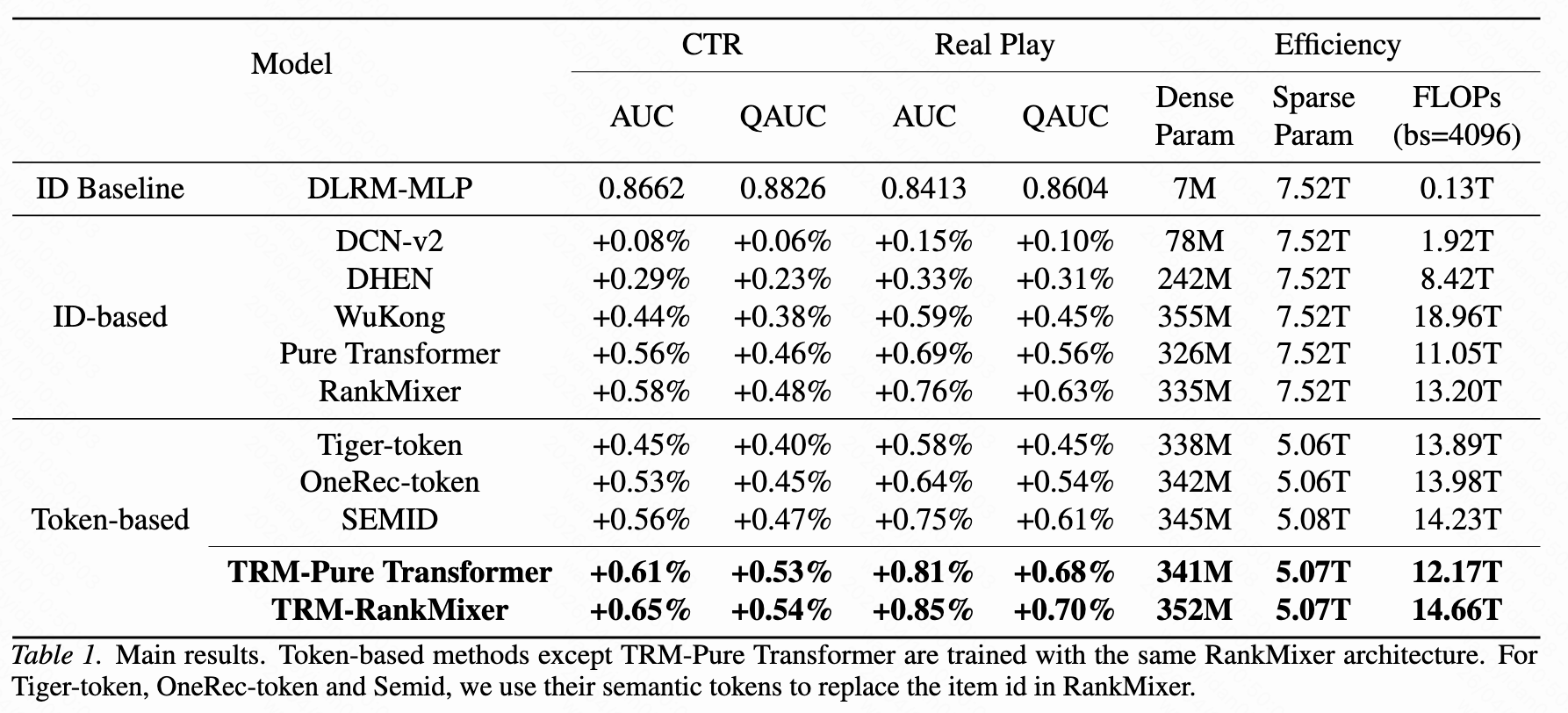
-
Scaling Law分析:
- 传统ID方法在模型增大时性能饱和
- TRM展现出良好的scaling特性
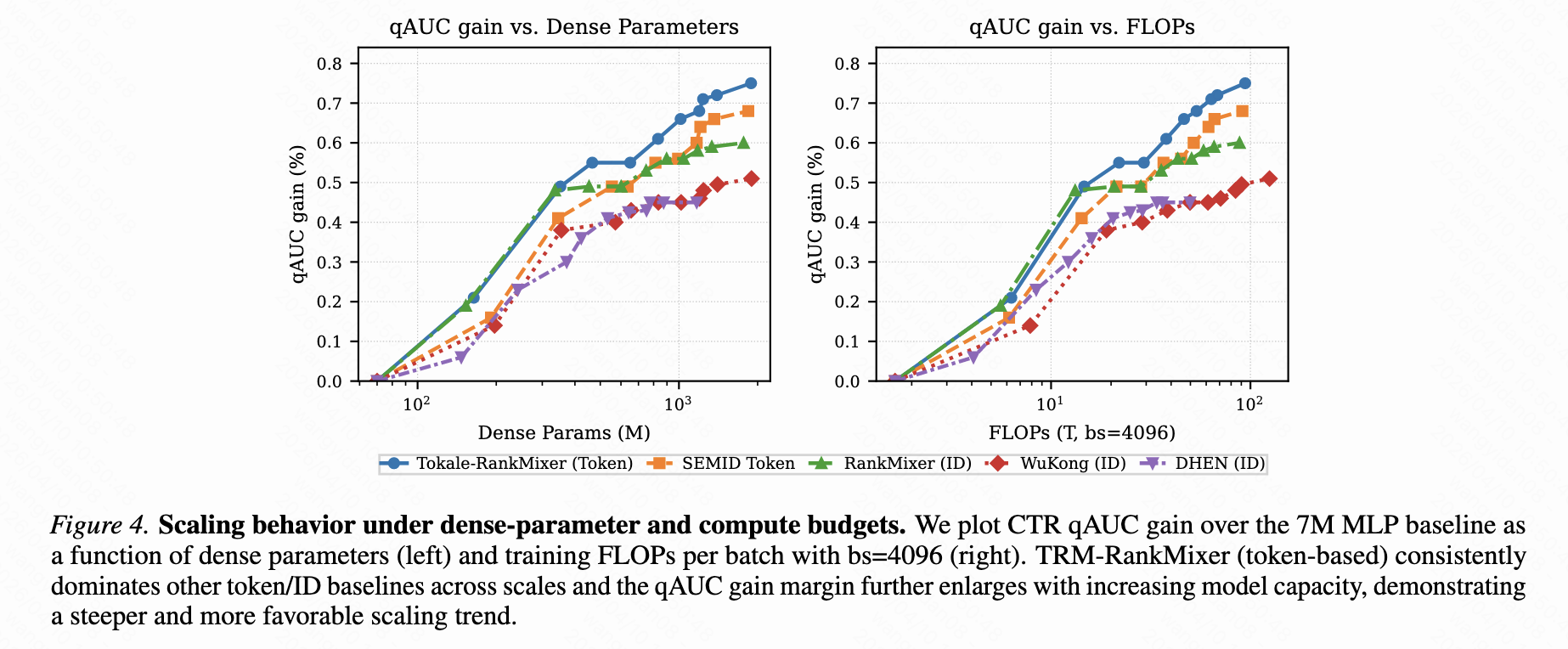
-
消融实验:
- 混合token贡献最大(+0.31 AUC)
- 生成目标也有显著增益(+0.18 AUC)
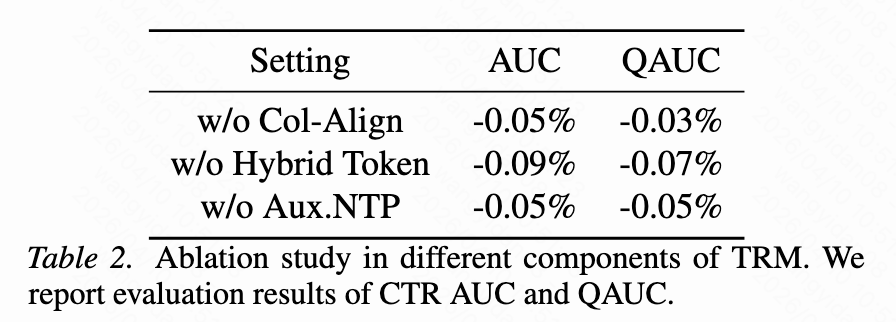
3.3 线上A/B测试
在TikTok视频搜索场景部署352M参数的TRM模型,对比原有7M参数的DLRM模型:
- QAUC提升0.54%
- CTR显著提高
- 服务延迟保持在可接受范围

4. 技术延伸与实践建议
4.1 适用场景分析
TRM框架特别适合以下场景:
- 物品流动性高的系统(如短视频、新闻推荐)
- 冷启动问题严重的领域
- 多模态内容丰富的应用
- 模型规模持续增长的业务
对于物品相对稳定、内容特征少的场景(如电商长尾商品),传统ID方法可能仍具优势。
4.2 实现注意事项
-
多模态特征提取:
- 视觉模型建议使用CLIP等预训练架构
- 文本特征应融合标题、ASR等多来源信息
- 注意不同模态的时间对齐问题
-
tokenization优化:
- RQ-Kmeans的聚类数需要平衡效果和效率
- BPE组合token的长度不宜过长(通常2-3个基token)
- 定期更新token词汇表以适应分布变化
-
工程实现技巧:
- 生成任务可以使用teacher forcing加速收敛
- 在线服务时缓存token序列减少计算开销
- 对长尾token设计特殊的降级策略
4.3 未来改进方向
- 动态token更新:当前token词汇表静态,可探索增量式更新机制
- 跨领域迁移:研究如何将token体系迁移到新业务领域
- 交互式生成:结合用户实时反馈调整生成过程
- 多模态生成:不仅生成token,还能生成推荐理由等内容
在实际业务中落地TRM框架时,建议从小流量实验开始,重点关注:
- 新物品的冷启动效果提升
- 老物品的长尾效应改善
- 模型大小与效果的非线性关系
- 线上服务的性能波动
这项研究为推荐系统提供了一种去ID化的新范式,通过语义token实现了更好的知识共享和模型扩展性。虽然完全摒弃ID特征需要改变许多现有架构,但其带来的性能优势和scaling潜力值得深入探索。