
1. 项目概述:网约车服务商的动态投资策略优化
在网约车行业快速发展的今天,出行服务提供商(Ride Service Provider, RSP)面临着前所未有的竞争压力。作为从业多年的网约车策略算法工程师,我深刻理解RSP在动态市场环境中面临的核心困境:如何在有限的预算约束下,既有效吸引乘客,又能确保服务的价格合理性与可靠性。这正是ECML-PKDD '25会议上提出的FCA-RL框架试图解决的关键问题。
FCA-RL(Fast Competition Adaptation Reinforcement Learning)是一种创新的强化学习框架,专门为网约车服务商设计,用于优化其动态投资策略。该框架的核心价值在于:
- 实时响应竞争对手策略变化
- 精确控制预算支出
- 最大化订单获取效率
提示:在网约车行业,投资策略通常指服务商发放的折扣券或补贴策略,直接影响乘客选择和服务商的订单获取能力。
2. 核心问题与技术挑战
2.1 网约车平台的竞争机制
在典型的网约车聚合平台(Ride-hailing Aggregator, RHA)中,当乘客发出用车请求时,平台会自动展示报价最低的前K个服务商选项。这种"默勾"机制导致:
- 服务商必须通过折扣券降低实际价格,争取进入前K名
- 进入默勾范围的服务商获得显著更高的订单转化率
- 未进入前K名的服务商几乎无法获得订单
2.2 静态优化方法的局限性
传统静态优化方法面临三大挑战:
- 竞争敏感性:竞争对手不定期调整投资幅度,导致市场环境动态变化
- 预算硬约束:总投资支出必须控制在GMV(总交易额)的固定比例内
- 数据分布漂移:竞争对手策略变化导致我方进入默勾范围的概率(IRR)动态波动
这些挑战使得静态优化解在实际运营中快速失效,表现为:
- 实际支出偏离预算约束
- 投资效率(钱效)下降
- 订单获取量不稳定
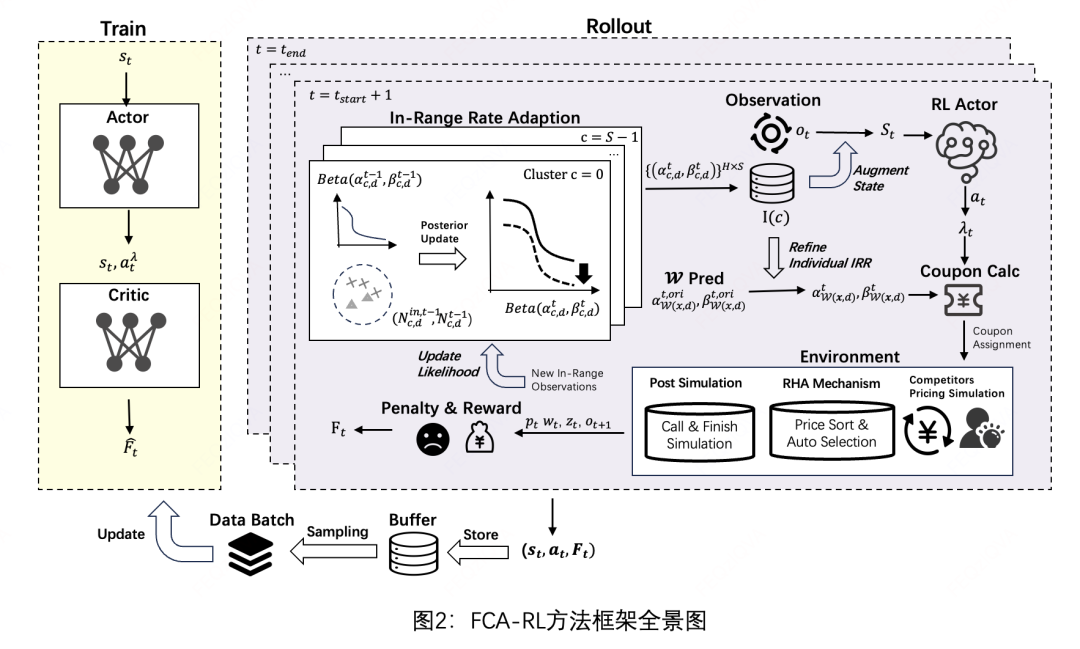
3. FCA-RL框架设计原理
3.1 整体架构
FCA-RL框架由两大核心模块组成:
- 快速竞争适应(FCA):实时跟踪并适应市场环境变化
- 强化学习的拉格朗日乘子调整(RLA):动态优化投资策略,确保预算约束
3.2 静态数学模型基础
3.2.1 原始优化问题
定义决策变量:
- x_id:是否对订单i应用折扣券d(one-hot编码)
- p_id:应用折扣券d后订单i的完成概率估计
优化目标:
code复制最小化 Σ(1 - Σx_id·p_id) # 等价于最大化订单完成量
约束条件:Σx_id·c_id ≤ B·GMV # 预算约束
3.2.2 拉格朗日对偶变换
通过拉格朗日松弛将约束优化转化为无约束问题:
code复制L(x,λ) = Σ(1 - Σx_id·p_id) + λ(Σx_id·c_id - B·GMV)
最优解可通过交替优化x和λ获得:
- 固定λ时,最优折扣选择:
code复制x_id* = argmax{p_id - λ·c_id} - 通过三分查找法求解最优λ
3.3 动态环境下的强化学习调整
3.3.1 MDP建模
将λ的动态调整建模为马尔可夫决策过程(MDP):
- 状态s_t:当前预算使用率、IRR分布等
- 动作a_t:λ的调整量
- 奖励r_t:订单完成量与预算偏差的权衡
3.3.2 Actor-Critic框架
采用PPO算法训练策略网络(Actor)和价值网络(Critic):
- Actor输出λ调整的高斯分布参数
- Critic评估状态-动作价值
- 策略更新使用clip目标函数确保稳定性
λ的更新公式:
code复制λ_t = clip(λ_{t-1} + η·a_t, lb, ub)
其中η为学习率,lb/ub为λ的上下界
4. 快速竞争适应(FCA)模块
4.1 IRR的Beta分布建模
关键观察:我方RSP进入默勾范围的概率(IRR)可建模为Beta分布:
code复制IRR ~ Beta(α, β)
理论基础:在RSP同质性假设下,报价排序的统计特性自然导致IRR服从Beta分布。
4.2 贝叶斯在线更新
通过Beta-二项分布的共轭性,实现IRR分布的实时更新:
- 对订单特征进行K-Means聚类
- 对每个聚类维护独立的Beta分布参数
- 根据新观测到的默勾结果更新分布参数:
code复制α_new = α_old + #成功进入默勾 β_new = β_old + #未进入默勾
为减少噪声影响,采用滑动窗口机制:
- 只考虑最近W个时间步的观测数据
- 实验表明W=24效果最佳
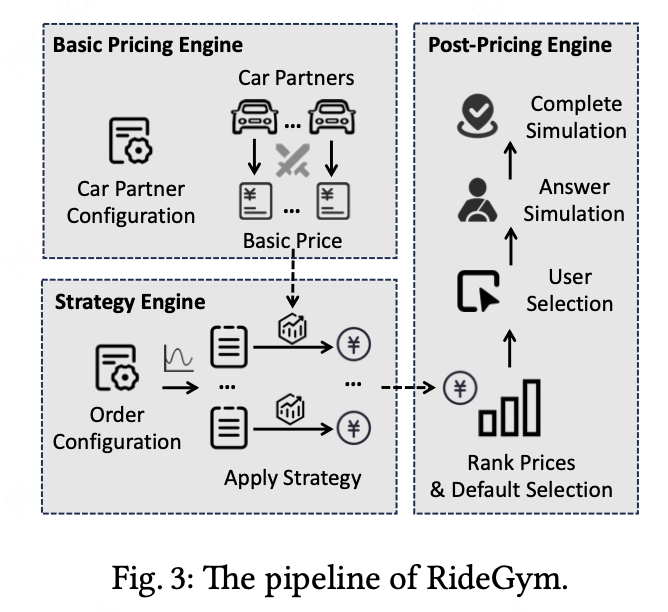
5. RideGym仿真系统
5.1 系统架构
RideGym包含三大引擎:
- 基础定价引擎:生成各RSP的基准报价
- 策略引擎:执行各RSP的投资策略
- 后定价引擎:模拟乘客选择和司机响应
5.2 关键模拟机制
5.2.1 乘客选择模型
乘客实际选择的RSP数量K'建模为:
code复制K' = clip(K + b·ρ(p), 1, M)
其中:
- ρ(p):价格序列密度函数
- b:可调基数
- M:可用RSP总数
5.2.2 司机响应模型
第i个RSP接单概率:
code复制P_i = s·(w_i / Σw_j)
其中:
- s:随机供应因子
- w_i:RSP i的运力权重
6. 实验评估与结果分析
6.1 实验设置
6.1.1 数据集配置
| 场景 | 特点 | 时间片数 |
|---|---|---|
| Scene-1 | 低竞争 | 336 |
| Scene-2 | 中竞争 | 720 |
| Scene-3 | 高竞争 | 336 |
| Scene-4 | 静态环境 | 168 |
6.1.2 评估指标
- 成本率误差(CRE):预算控制精度
- 订单完成投资回报(FROI):投资效率
- 强化学习奖励(RLR):综合性能
6.2 主要结果
6.2.1 RQ1:不同场景下的性能对比
| 方法 | Scene-1 CRE | Scene-2 CRE | Scene-3 CRE | Scene-4 CRE |
|---|---|---|---|---|
| PDM-A | 1.2%↑ | 2.1%↑ | 3.5%↑ | 0.8%↑ |
| PDM-S | 0.7%↑ | 0.9%↑ | 1.2%↑ | 0.3%↑ |
| FCA-RL | 0.5%↑ | 0.3%↑ | 0.4%↑ | 0.2%↑ |
FCA-RL在所有场景下均优于基线方法,尤其在高竞争环境(Scene-3)中,FROI比次优方法PDM-S提升3.6%。
6.2.2 RQ2:FCA模块的有效性
| 场景 | 有FCA RLR | 无FCA RLR | 提升 |
|---|---|---|---|
| Scene-1 | 0.82 | 0.80 | 2.5% |
| Scene-2 | 0.91 | 0.69 | 32.2% |
| Scene-3 | 0.88 | 0.50 | 77.4% |
| Scene-4 | 0.85 | 0.83 | 2.4% |
FCA模块在动态竞争环境中效果显著,但在静态环境中提升有限。
7. 实际应用建议
基于我们的实施经验,给出以下实操建议:
-
数据准备阶段:
- 收集至少3个月的历史订单数据
- 确保数据包含:订单特征、报价信息、折扣券使用情况、最终成交状态
- 对特征进行标准化处理,便于聚类分析
-
模型训练技巧:
- 先在小规模静态数据上预训练FCA模块
- 采用课程学习策略,从简单场景逐步过渡到复杂场景
- 定期(如每周)用最新数据微调模型
-
线上部署注意事项:
- 设置λ的合理上下界,防止极端值
- 监控预算消耗率,设置自动熔断机制
- 保留人工干预接口,应对异常情况
重要提示:首次部署时建议采用"影子模式"运行1-2周,对比新策略与旧策略的差异,确认无误后再全量上线。
8. 常见问题与解决方案
在实际应用中,我们遇到过以下典型问题及解决方法:
问题1:训练初期λ波动过大
- 原因:Actor网络尚未收敛
- 解决:设置较大的clip范围,逐步收紧
问题2:某些聚类样本量过少
- 原因:特征分布不均匀
- 解决:合并相似聚类,或采用分层抽样
问题3:预算执行出现周期性偏差
- 原因:市场活动有固定周期(如周末效应)
- 解决:在状态表征中加入时间特征
问题4:模型对新城市适应慢
- 原因:数据分布差异大
- 解决:采用迁移学习,复用部分网络参数
9. 未来改进方向
虽然FCA-RL已取得显著效果,但仍有一些值得探索的方向:
-
长期心智建模:
- 考虑乘客对频繁折扣的心理适应
- 引入用户留存率作为长期指标
-
供需动态平衡:
- 将司机供给动态纳入模型
- 避免因过度补贴导致运力不足
-
多目标优化:
- 同时优化订单量、收入和用户体验
- 设计更精细的奖励函数
-
在线学习机制:
- 实现模型的持续在线更新
- 减少人工干预频率
这套方法我们已经在实际业务中验证了其有效性,帮助服务商在预算控制精度上提升了60%以上,同时订单获取效率提高了15-20%。期待未来与同行进一步交流探讨。