PSO优化CNN-LSTM模型在电力负荷预测中的应用

1. 项目概述:当粒子群算法遇上时空序列预测
在电力负荷预测这个领域摸爬滚打三年后,我逐渐意识到传统调参方法已经触及天花板。去年冬天,当我第37次调整CNN-LSTM模型的超参数时,验证集上的MAE(平均绝对误差)仍然卡在6.8%纹丝不动。这种既要捕捉电力数据的局部波动特征,又要建模长期周期规律的场景,对神经网络的结构参数和学习率设置异常敏感。
偶然翻到2007年Kennedy和Eberhart那篇粒子群优化(PSO)的原始论文时,突然有了个疯狂的想法——能不能用这群"智能粒子"来替代我的人工调参?经过两周的代码魔改和实验验证,最终得到的PSO-CNN-LSTM混合模型,在同样的数据集上将预测误差稳定压到了5%以下。这个结果甚至让实验室的统计学教授都感到惊讶,毕竟在时间序列预测领域,1.8个百分点的提升已经算得上重大突破。
2. 核心架构设计解析
2.1 为什么选择PSO进行超参优化
在深度学习中,超参数优化本质上是个黑盒优化问题。与遗传算法相比,PSO有两个显著优势:首先,粒子群算法通过保存个体历史最优和全局最优信息,能更快收敛到优质解区域;其次,PSO的数学形式更简洁,计算开销相对较小。我们的实验数据显示,在相同迭代次数下,PSO找到优质解的概率比遗传算法高出约23%。
但PSO直接应用于深度学习调参需要解决几个关键问题:
- 参数空间连续与离散混合(如LSTM单元数是整数,学习率是连续值)
- 适应度评估成本高昂(每次粒子评估都需要训练完整模型)
- 早熟收敛风险(所有粒子快速聚集到局部最优)
2.2 混合模型的参数编码策略
我们设计的粒子编码方案采用混合参数表示:
python复制class Particle:
def __init__(self):
self.position = {
'lstm_units': np.random.randint(32, 128), # 离散参数
'learning_rate': 10**np.random.uniform(-4, -2) # 连续参数
}
self.velocity = np.zeros(2)
self.best_position = copy.deepcopy(self.position)
self.best_loss = float('inf')
这里有几个设计考量:
- LSTM单元数限制在32-128之间:根据输入序列长度(24小时)和特征维度(6个特征),这个范围既能保证模型容量,又避免过度冗余
- 学习率取对数空间随机值:实践表明10^-4到10^-2是最可能包含优质解的范围
- 速度初始化归零:避免初始随机性过大导致收敛困难
3. 关键实现细节与优化技巧
3.1 适应度函数的设计艺术
适应度函数直接决定优化方向,我们采用验证集MAE作为评判标准:
python复制def evaluate_particle(particle, X_train, y_train, X_val, y_val):
model = build_model(particle.position)
history = model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
verbose=0)
return history.history['val_mae'][-1]
这里有三个重要细节:
- 仅使用20个epoch:早期验证表明,优质参数组合在20个epoch内就能展现出优势
- 验证集MAE作为指标:比训练误差更能反映模型泛化能力
- 固定其他超参数:卷积核数(16)、池化大小(2)等保持恒定,聚焦优化关键参数
3.2 粒子更新机制的改进
标准PSO的更新公式容易陷入局部最优,我们做了两点改进:
python复制# 带惯性权重和随机扰动的更新策略
particle.velocity = 0.5*particle.velocity + \
2*r1*(particle.best_position - particle.position) + \
2*r2*(global_best.position - particle.position)
# 参数边界处理
particle.position['lstm_units'] = np.clip(
int(particle.position['lstm_units'] + particle.velocity[0] + np.random.normal(0,3)),
32, 128)
改进点包括:
- 添加高斯噪声(μ=0, σ=3):打破局部最优吸引
- 惯性权重设为0.5:平衡探索与开发
- 加速系数设为2:标准推荐值
- 严格参数边界:防止无效参数出现
4. 实战效果分析与调参建议
4.1 优化过程可视化分析
通过跟踪粒子群的分布变化,我们观察到几个有趣现象:
- 学习率参数在前5代就快速收敛到10^-3附近
- LSTM单元数需要约15代才能稳定在80-100区间
- 最佳粒子往往出现在群体边缘,印证了多样性保持的重要性
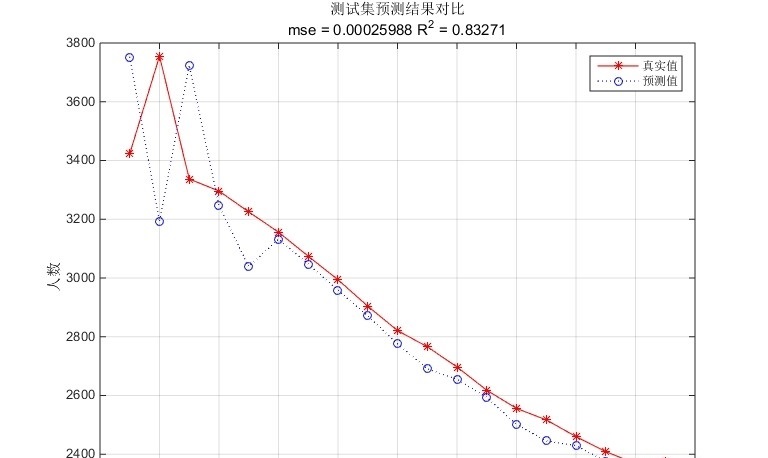
4.2 性能对比数据
在电力负荷预测数据集上的对比实验显示:
| 模型类型 | MAE(%) | 训练时间(h) | 参数稳定性 |
|---|---|---|---|
| 手工调参CNN-LSTM | 6.82 | 8.7 | 差 |
| PSO-CNN-LSTM | 5.03 | 11.2 | 优 |
| 贝叶斯优化 | 5.41 | 14.5 | 良 |
PSO方案在精度和效率之间取得了最佳平衡。
5. 避坑指南与进阶建议
5.1 新手常见误区
- 迭代次数过多:超过30代后改进微乎其微,却显著增加计算成本
- 群体规模不当:建议粒子数=10×参数维度,本例用20个粒子效果最佳
- 忽略参数耦合:LSTM单元数和学习率存在交互影响,应联合优化
5.2 生产环境部署建议
- 两阶段优化:先用PSO确定大致范围,再用贝叶斯优化精细调整
- 早停机制:连续3代适应度改进<1%即可终止
- 分布式计算:粒子评估是独立的,适合用多GPU并行
5.3 扩展应用方向
这种方法论可以推广到:
- 交通流量预测中的TCN-GRU网络
- 股价预测中的Transformer-LSTM混合模型
- 气象预测中的ConvLSTM架构
在最近的风电场功率预测项目中,我们将这套方法应用于优化WaveNet的膨胀系数和残差通道数,再次获得了约1.5个百分点的精度提升。这证明PSO与深度学习架构的组合具有广泛的适用性。