机器学习分类任务:数据增广与优化算法实战

1. 分类任务基础与核心挑战
在机器学习领域,分类任务是最基础也最具代表性的问题类型之一。简单来说,分类就是让模型学会根据输入数据预测其所属的类别标签。比如识别图片中是猫还是狗,判断邮件是否为垃圾邮件,或者诊断医疗影像是否显示某种疾病。
分类模型的核心工作原理是通过数据和对应的真实标签(ground truth)计算损失函数(loss),然后利用这个损失值来计算梯度并更新模型参数。这个过程看似直接,但实际操作中会遇到几个关键挑战:
- 数据多样性不足:训练数据可能无法覆盖真实场景中的所有变化
- 模型收敛困难:特别是深层网络容易出现梯度消失或爆炸
- 标注成本高昂:获取大量高质量标注数据代价昂贵
提示:分类任务中,数据质量往往比算法选择更重要。在资源有限的情况下,优先考虑如何获取和增强高质量数据。
2. 图像分类中的数据增广技术
2.1 为什么需要数据增广
人类视觉系统具有强大的不变性识别能力 - 我们能够轻易识别旋转、缩放或部分遮挡的物体。但对于机器学习模型来说,这些变换可能使特征提取变得异常困难。下图展示了同一张图片经过不同变换后的效果:

数据增广的核心思想是通过对原始训练图片施加各种变换(旋转、翻转、裁剪、颜色调整等),生成更多样的训练样本。这相当于在不增加新数据的情况下,扩大了训练集的规模和多样性。
2.2 常用图像增广技术
-
几何变换:
- 随机旋转(通常±15-30度)
- 水平/垂直翻转
- 随机裁剪和缩放
- 透视变换
-
颜色空间变换:
- 亮度、对比度调整
- 色相、饱和度变化
- 添加噪声
-
高级增广技术:
- MixUp:两张图片线性混合
- CutMix:用另一张图片的部分区域替换
- AutoAugment:自动学习最优增广策略

实操心得:增广强度需要谨慎调整。太弱可能效果不明显,太强则可能破坏原始图像语义。建议从温和的增广开始,逐步增加强度观察模型表现。
3. 优化算法:从Adam到AdamW
3.1 Adam优化器解析
Adam(Adaptive Moment Estimation)是目前深度学习中最流行的优化算法之一。它结合了两种经典优化方法的优点:
- 动量(Momentum):考虑历史梯度,加速收敛
- RMSProp:自适应调整学习率
Adam的核心公式可以表示为:
code复制m_t = β1*m_{t-1} + (1-β1)*g_t # 一阶矩估计
v_t = β2*v_{t-1} + (1-β2)*g_t^2 # 二阶矩估计
θ_t = θ_{t-1} - η*m_t/(√v_t + ε) # 参数更新
其中β1和β2通常设为0.9和0.999,控制历史信息的衰减率。
3.2 AdamW:解耦权重衰减
传统Adam将L2正则化(权重衰减)直接融入梯度计算中,这可能导致正则化效果不理想。AdamW对此进行了改进:
- 将权重衰减从梯度计算中解耦
- 作为独立操作在参数更新时直接应用
改进后的更新公式:
code复制θ_t = θ_{t-1} - η*(m_t/(√v_t + ε) + λ*θ_{t-1})
其中λ是权重衰减系数。这种解耦方式使得正则化效果更加稳定可靠。

参数选择建议:对于计算机视觉任务,AdamW的学习率通常设为3e-4到1e-3,权重衰减1e-2到1e-3。NLP任务可能需要更小的学习率(1e-5到5e-5)。
4. 分类任务输出处理与评估
4.1 argmax函数与决策边界
分类模型的最后一层通常是全连接层,输出每个类别的"得分"。通过softmax函数将这些得分转换为概率分布:
code复制p_i = exp(z_i)/∑exp(z_j)
然后使用argmax函数确定预测类别:
code复制predicted_class = argmax(p)
这个决策过程实际上是在特征空间中寻找最优的分离边界(决策边界)。对于线性分类器,这是一个超平面;对于深层网络,可能是高度复杂的非线性边界。

4.2 多分类与多标签分类
根据问题性质,分类任务可以分为:
| 类型 | 特点 | 输出处理 | 损失函数 |
|---|---|---|---|
| 二分类 | 两个互斥类别 | sigmoid + 阈值 | BCE |
| 多分类 | 多个互斥类别 | softmax + argmax | CE |
| 多标签 | 多个非互斥类别 | sigmoid + 多阈值 | BCE |
注意事项:多标签分类中,每个类别是独立的判断,不能简单使用softmax。常见错误是将多标签问题误用多分类方法处理。
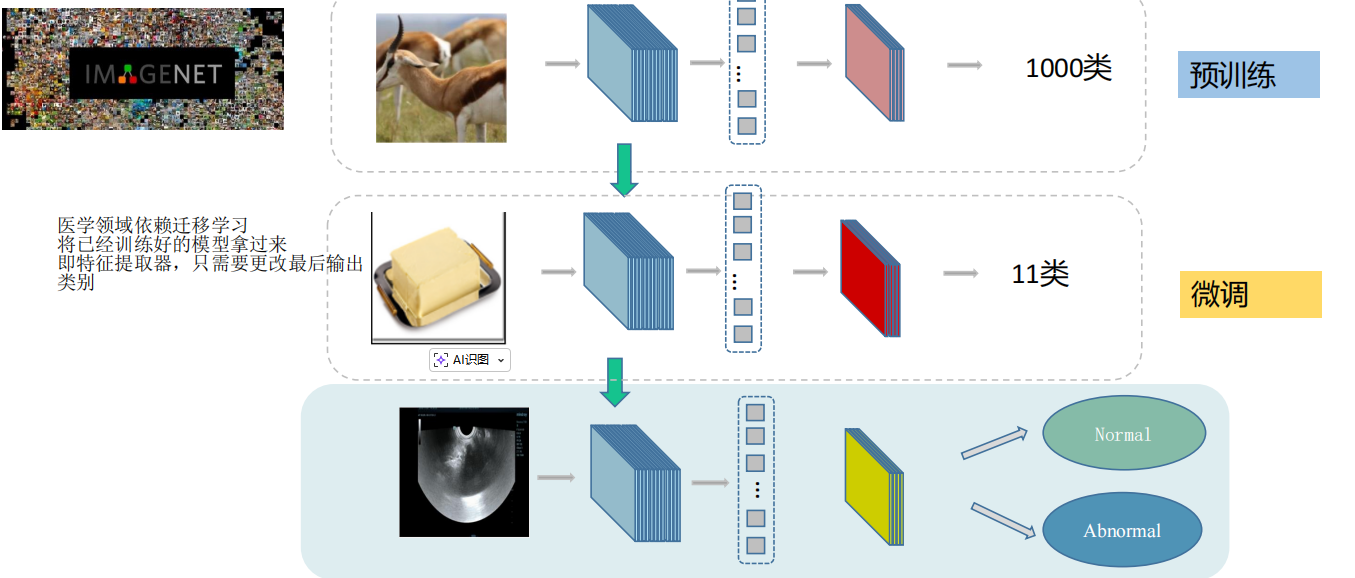
5. 迁移学习实战技巧
5.1 预训练模型的价值
迁移学习的核心思想是利用在大规模数据集上预训练的模型,通过微调(fine-tuning)适应特定任务。这种方法特别有效,因为:
- 预训练模型已经学习到了通用的视觉特征(边缘、纹理、形状等)
- 可以大幅减少训练数据和计算资源需求
- 在小数据集上也能获得不错的表现
常见的预训练模型架构包括:
- 计算机视觉:ResNet, EfficientNet, ViT
- 自然语言处理:BERT, GPT, T5

5.2 迁移学习实践策略
- 特征提取器:冻结所有层,只训练新添加的分类头
- 部分微调:冻结底层,微调上层
- 完全微调:解冻所有层进行训练
选择策略的经验法则:
| 数据量 | 推荐方法 | 学习率 |
|---|---|---|
| 非常小(<1k) | 特征提取 | 1e-3~1e-4 |
| 中等(1k~10k) | 部分微调 | 1e-4~1e-5 |
| 大量(>10k) | 完全微调 | 1e-5~5e-6 |
实操技巧:使用学习率预热(warmup)可以显著改善微调稳定性。前几个epoch线性增加学习率,避免初期的大梯度破坏预训练特征。
6. 半监督学习:利用未标注数据
6.1 半监督学习原理
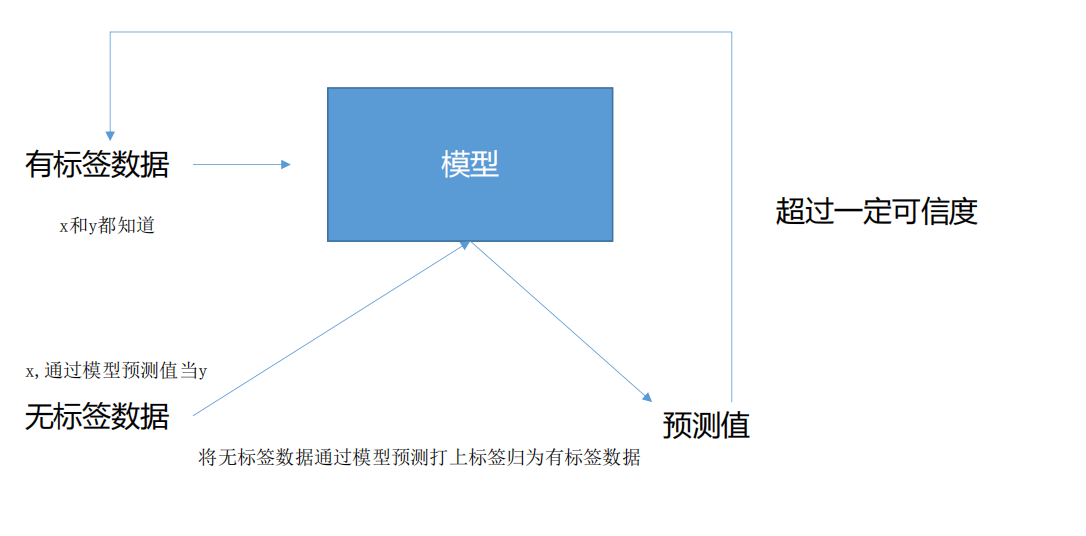
标注数据的获取成本往往很高,而未标注数据却很容易大量收集。半监督学习正是利用这一现实,通过以下方式提升模型性能:
- 用有标签数据训练初始模型
- 用该模型预测无标签数据的伪标签(pseudo-label)
- 用所有数据(有标签+伪标签)重新训练模型
这个过程可以迭代进行,逐步提高模型质量。
6.2 一致性正则化
现代半监督学习方法(如FixMatch)引入了更高级的一致性正则化:
- 对同一无标签样本应用不同增广
- 强制模型对这些增广产生一致预测
- 高置信度预测作为伪标签
这种方法显著提升了伪标签的质量和稳定性。

注意事项:伪标签方法可能放大模型原有偏见。建议监控各类别的预测分布,必要时进行校准或重新采样。
7. 神经网络训练全流程
7.1 标准训练流程
一个完整的神经网络训练流程包括以下关键步骤:
-
数据准备:
- 划分训练集/验证集/测试集
- 实现数据增广pipeline
- 数据标准化
-
模型构建:
- 选择合适架构
- 初始化参数
- 定义损失函数
-
训练循环:
- 前向传播
- 损失计算
- 反向传播
- 参数更新
-
模型评估:
- 验证集性能监控
- 早停(early stopping)
- 保存最佳模型
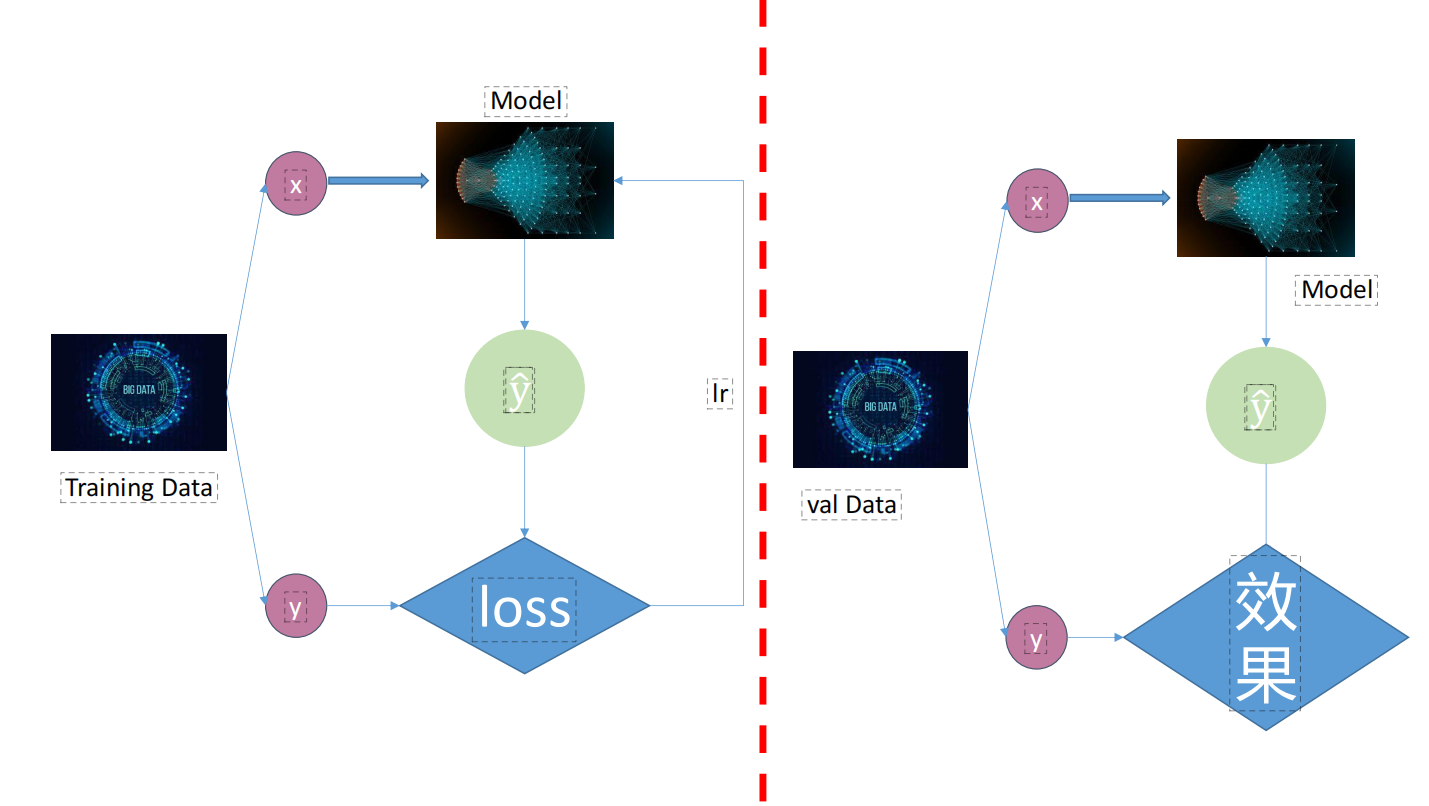
7.2 验证与模型选择
验证集在训练过程中扮演着至关重要的角色:
- 监控模型是否过拟合
- 用于超参数调优
- 决定何时停止训练
常见的验证策略:
| 策略 | 优点 | 缺点 |
|---|---|---|
| 简单划分 | 实现简单 | 小数据集效果差 |
| K折交叉验证 | 数据利用率高 | 计算成本高 |
| 留出法 | 评估稳定 | 需要足够数据 |

经验分享:在资源允许的情况下,建议至少保留20%数据作为测试集,完全不参与任何训练和调优过程,这样才能获得真实的模型性能评估。
8. 分类任务实战技巧与避坑指南
8.1 类别不平衡处理
现实数据中经常遇到类别分布极度不均衡的情况。常用解决方法:
-
重采样:
- 过采样少数类(如SMOTE)
- 欠采样多数类
-
损失函数调整:
- 类别加权交叉熵
- Focal Loss
-
评估指标选择:
- 优先考虑召回率、F1分数
- 谨慎使用准确率
8.2 学习率策略
学习率是影响训练效果的最关键超参数之一:
- 学习率预热:初始阶段线性增加学习率
- 余弦退火:周期性变化学习率
- 周期性重启:突然增大学习率跳出局部最优
8.3 常见问题排查
遇到模型表现不佳时,可以按以下步骤排查:
-
数据问题:
- 检查标签是否正确
- 确认数据增广没有破坏语义
- 验证数据分布是否一致
-
模型问题:
- 检查梯度是否正常传播
- 确认初始化是否合理
- 评估模型容量是否足够
-
优化问题:
- 学习率是否合适
- 批次大小是否合理
- 正则化强度是否适当
在实际项目中,我通常会先在一个小的数据子集上过拟合(确保模型有能力学习),然后再扩展到完整数据集调整正则化。这种方法能快速区分是模型能力问题还是优化问题。