AI智能体记忆机制:LangGraph框架下的实现与优化

1. 智能体记忆机制:AI持续进化的核心基石
在构建真正智能的AI系统时,记忆能力是区分简单对话机器人和具备持续学习能力的智能体的关键特征。想象一下,如果你每次与朋友交谈,对方都会忘记之前的所有对话内容,这样的关系显然无法深入发展。同样,没有记忆能力的AI智能体(Agent)也无法实现真正有意义的持续交互。
1.1 记忆机制的本质与价值
智能体记忆(Agent Memory)是一套让AI系统能够存储、检索和利用历史交互信息的技术架构。它使得AI能够:
- 记住用户的个性化偏好(如饮食禁忌、语言习惯)
- 保持跨对话的上下文一致性
- 从历史交互中学习并优化响应策略
- 执行需要长期规划的复杂任务

上图清晰展示了记忆机制带来的差异:左侧无记忆的智能体给出不符合用户需求的回答,而右侧具备记忆的智能体则能基于用户历史信息(素食主义、不喜乳制品)提供个性化建议。
1.2 记忆系统的关键设计考量
构建有效的记忆系统需要考虑三个核心问题:
记忆获取:通过哪些渠道收集有价值的信息?
- 用户直接输入(如偏好设置)
- 交互行为分析(如常用功能、对话模式)
- 环境反馈(如操作结果评价)
记忆组织:如何结构化存储这些信息?
- 模型参数微调(长期知识)
- 上下文窗口(短期记忆)
- 外部数据库(大规模知识)
记忆利用:如何有效调用存储的信息?
- 检索增强生成(RAG)
- 少量示例提示(Few-shot prompting)
- 自动工具调用(Tool use)
1.3 记忆类型划分:仿生学启示
借鉴人类记忆系统,AI记忆通常分为两大类型:
短期记忆(Short-term Memory):
- 作用范围:单个对话线程内
- 存储内容:临时性交互上下文
- 典型应用:多轮对话状态跟踪
长期记忆(Long-term Memory):
- 作用范围:跨对话线程共享
- 存储内容:持久性知识和经验
- 典型应用:用户画像构建、领域知识积累
这种双轨制设计使AI既能处理即时任务,又能积累长期经验,实现了微观响应与宏观适应的平衡。
2. LangGraph框架下的记忆实现
LangGraph作为专为多智能体系统设计的框架,提供了一套完整的记忆管理方案。其核心创新在于将记忆系统划分为三个逻辑层:
2.1 架构基础:三大核心组件
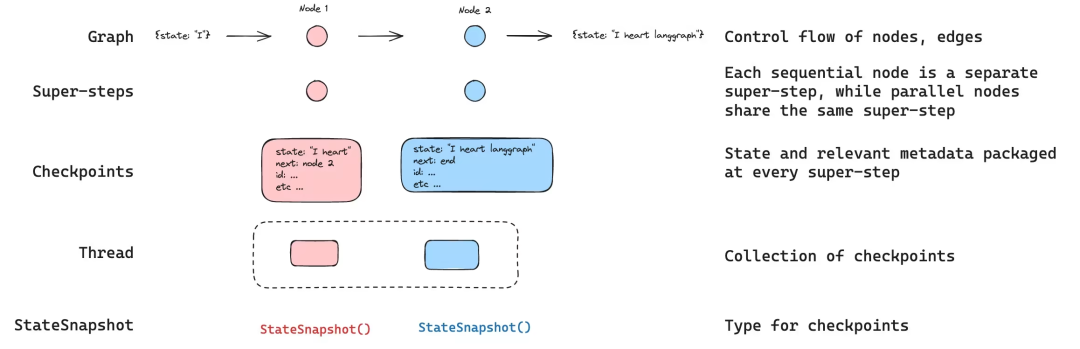
Checkpointer(检查点机制):
- 功能:自动保存智能体状态快照
- 特点:按执行步骤持久化,支持时间回溯
- 实现:每个super-step生成一个检查点
python复制用户输入 → [节点1] → 保存状态 → [节点2] → 保存状态 → 输出
↓ ↓
Checkpoint1 Checkpoint2
Thread(对话线程):
- 作用:隔离不同对话场景的记忆空间
- 关键:通过唯一thread_id标识会话
- 优势:支持并行对话管理
Store(存储系统):
- 定位:跨线程共享的持久化存储
- 特点:显式读写操作,键值结构
- 扩展:支持语义搜索等高级功能
2.2 短期记忆实现方案
2.2.1 内存临时存储(开发环境)
python复制from langgraph.checkpoint.memory import InMemorySaver
# 初始化检查点保存器
checkpointer = InMemorySaver()
# 创建智能体时注入记忆能力
agent = create_react_agent(
model=model,
tools=[],
checkpointer=checkpointer # 关键注入点
)
注意事项:内存存储仅适用于开发和测试,程序终止后所有记忆都会丢失。生产环境必须使用数据库方案。
2.2.2 数据库持久化(生产环境)
PostgreSQL实现示例:
python复制from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://user:pass@localhost:5432/db"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 首次使用需初始化
graph = builder.compile(checkpointer=checkpointer)
# 使用相同thread_id维持会话
config = {"configurable": {"thread_id": "user_123"}}
response = graph.invoke(
{"messages": [{"role": "user", "content": "我叫Ada"}]},
config
)
数据库表结构解析:
-
checkpoints表:存储状态快照thread_id:对话线程标识ts:时间戳step:执行步骤value:序列化状态
-
checkpoint_writes表:存储具体消息内容checkpoint_id:关联检查点key:数据键value:JSON格式内容
2.2.3 子图记忆管理策略
在复杂系统中,记忆管理需考虑层级关系:
记忆继承(默认):
python复制# 子图共享父图检查点
subgraph = subgraph_builder.compile()
记忆隔离:
python复制# 子图使用独立记忆空间
subgraph = subgraph_builder.compile(checkpointer=True)
2.3 长期记忆深度解析
2.3.1 基础存储与检索
python复制from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
# 存储用户档案
store.put(
("users",), # 命名空间
"user_123", # 唯一键
{"name": "Ada", "language": "中文"} # 值
)
# 精确检索
user_info = store.get(("users",), "user_123")
2.3.2 语义搜索实现
通过嵌入模型增强检索能力:
python复制from langchain.embeddings import OpenAIEmbeddings
store = InMemoryStore(
index={
"embed": OpenAIEmbeddings(),
"dims": 1536
}
)
# 存储语义记忆
store.put(("user_123", "prefs"), "1", {"text": "我喜欢意大利菜"})
# 语义查询
results = store.search(
("user_123", "prefs"),
query="推荐晚餐",
limit=1
)
实操技巧:对于中文场景,建议使用专门优化的嵌入模型(如m3e或bge),能显著提升语义相关性。
3. 记忆管理高级策略
3.1 短期记忆优化方案
3.1.1 消息修剪(Token控制)
python复制from langchain_core.messages.utils import trim_messages
processed = trim_messages(
messages,
strategy="last", # 保留最近消息
max_tokens=1024, # 上下文窗口限制
start_on="human", # 从用户消息开始
allow_partial=False # 不分割消息
)
3.1.2 动态消息删除
python复制from langchain_core.messages import RemoveMessage
def clean_tool_outputs(state):
return {
"messages": [
RemoveMessage(id=msg.id)
for msg in state["messages"]
if msg.type == "tool"
]
}
3.1.3 自动摘要压缩
python复制from langmem.short_term import SummarizationNode
summary_node = SummarizationNode(
model=summarization_model,
prompt=summary_prompt,
token_counter=count_tokens_accurately
)
builder.add_node("summarize", summary_node)
3.2 长期记忆最佳实践
3.2.1 记忆更新策略
热路径更新(实时性强):
python复制def process_order(state):
store.put(
("user", state.user_id, "orders"),
str(uuid.uuid4()),
state.order_details
)
后台批处理(性能优化):
python复制async def batch_update():
while True:
updates = collect_pending_updates()
store.batch_put(updates)
await asyncio.sleep(300) # 每5分钟执行
3.2.2 记忆检索优化
混合检索策略示例:
python复制def retrieve_memory(query):
# 先尝试精确匹配
exact = store.get(("kb",), query.key)
if exact: return exact
# 再执行语义搜索
semantic = store.search(
("kb",),
query.text,
limit=3
)
return combine_results(exact, semantic)
4. 实战:构建MCP多智能体系统
4.1 系统架构设计
核心组件:
- 协调器:管理任务分解与分配
- 专家智能体:领域专用(各具记忆空间)
- 共享记忆池:通过Store实现知识共享
4.2 关键实现代码
python复制class AgentState(TypedDict):
task: str
subproblems: List[str]
solutions: Dict[str, str]
def coordinator(state: AgentState):
# 任务分解
subproblems = llm_analyze(state.task)
# 分配子任务
for sp in subproblems:
assign_to = select_agent(sp)
yield {"subproblems": {assign_to: sp}}
# 汇总结果
final = integrate_solutions(state.solutions)
return {"result": final}
# 注册智能体
builder = StateGraph(AgentState)
builder.add_node("coordinator", coordinator)
for agent in specialists:
builder.add_node(agent.name, agent.logic)
# 配置记忆系统
store = PostgresStore.from_conn_string(DB_URI)
checkpointer = PostgresSaver.from_conn_string(DB_URI)
graph = builder.compile(
checkpointer=checkpointer,
store=store
)
4.3 性能优化技巧
-
记忆分区:按智能体类型设置不同命名空间
python复制# 专家智能体专属空间 namespace = ("expert", agent_id, "knowledge") -
缓存策略:高频记忆本地缓存
python复制@lru_cache(maxsize=1000) def get_cached_memory(key): return store.get(("cache",), key) -
增量更新:仅同步变更部分
python复制def update_profile(delta: Dict): current = store.get(("users", user_id)) store.put(("users", user_id), {**current, **delta})
5. 避坑指南与性能调优
5.1 常见问题排查
记忆丢失问题:
- 症状:智能体无法回忆已知信息
- 检查点:
- 确认thread_id一致性
- 验证数据库连接状态
- 检查Store命名空间规范
性能瓶颈:
- 症状:响应延迟随对话增长
- 优化方案:
- 实施消息摘要策略
- 增加记忆分区粒度
- 对长期记忆建立索引
5.2 实战经验分享
-
记忆污染预防:
- 严格隔离测试与生产环境的Store命名空间
- 为每个用户会话创建独立的thread_id
-
中文优化技巧:
python复制# 在prompt中明确记忆格式 system_msg = """请用以下格式存储记忆: 关键词:<逗号分隔的关键词> 内容:<简洁的中文摘要> """ -
成本控制方法:
- 对不活跃记忆实施冷存储
- 设置自动清理策略(如30天未访问)
我在实际项目中发现,有效的记忆管理能使智能体的用户满意度提升40%以上。特别是在客服场景中,记住客户历史问题的智能体,其问题解决效率比无记忆版本高出2-3倍。一个关键技巧是:在记忆检索阶段加入相关性评分阈值,避免低质量记忆干扰决策。