2026年AI论文辅助工具评测与学术写作优化指南

1. 2026届AI论文工具现状与评测背景
作为经历过本科、硕士、博士完整学术训练的研究者,我深刻理解论文写作中那些令人抓狂的痛点:开题报告反复修改七稿仍被导师否决、文献综述写到凌晨三点发现逻辑链条断裂、查重时发现"学术化表达"竟被标红...这些场景催生了AI论文辅助工具的爆发式增长。2026年的工具市场已从早期的简单改写进化到全流程智能辅助,但随之而来的是两个核心问题:哪些工具真正能打?如何避开"用AI被AI坑"的陷阱?
本次横评选取了国内学术圈讨论热度最高的6款工具(千笔AI、aipasspaper、清北论文、豆包、kimi、deepseek),测试维度包括:
- 基础功能完备性(开题/文献/写作/降重)
- 学术合规性(AIGC率控制、参考文献质量)
- 特色功能差异化(图表生成、逻辑校验等)
- 实际使用体验(响应速度、交互设计)
测试环境说明:
- 使用同一篇经导师认可的硕士论文开题报告(管理科学与工程领域)
- 文献综述部分包含42篇中英文参考文献
- 原始文本AIGC率经知网检测为68%(典型AI辅助写作产物)
- 所有工具均使用默认参数设置,不进行人工调优
重要提示:学术诚信是底线,所有工具都应作为"智能助手"而非"代写枪手"。本次评测重点关注工具如何提升写作效率,而非规避学术规范。
2. 核心功能横向评测
2.1 开题报告构建能力对比
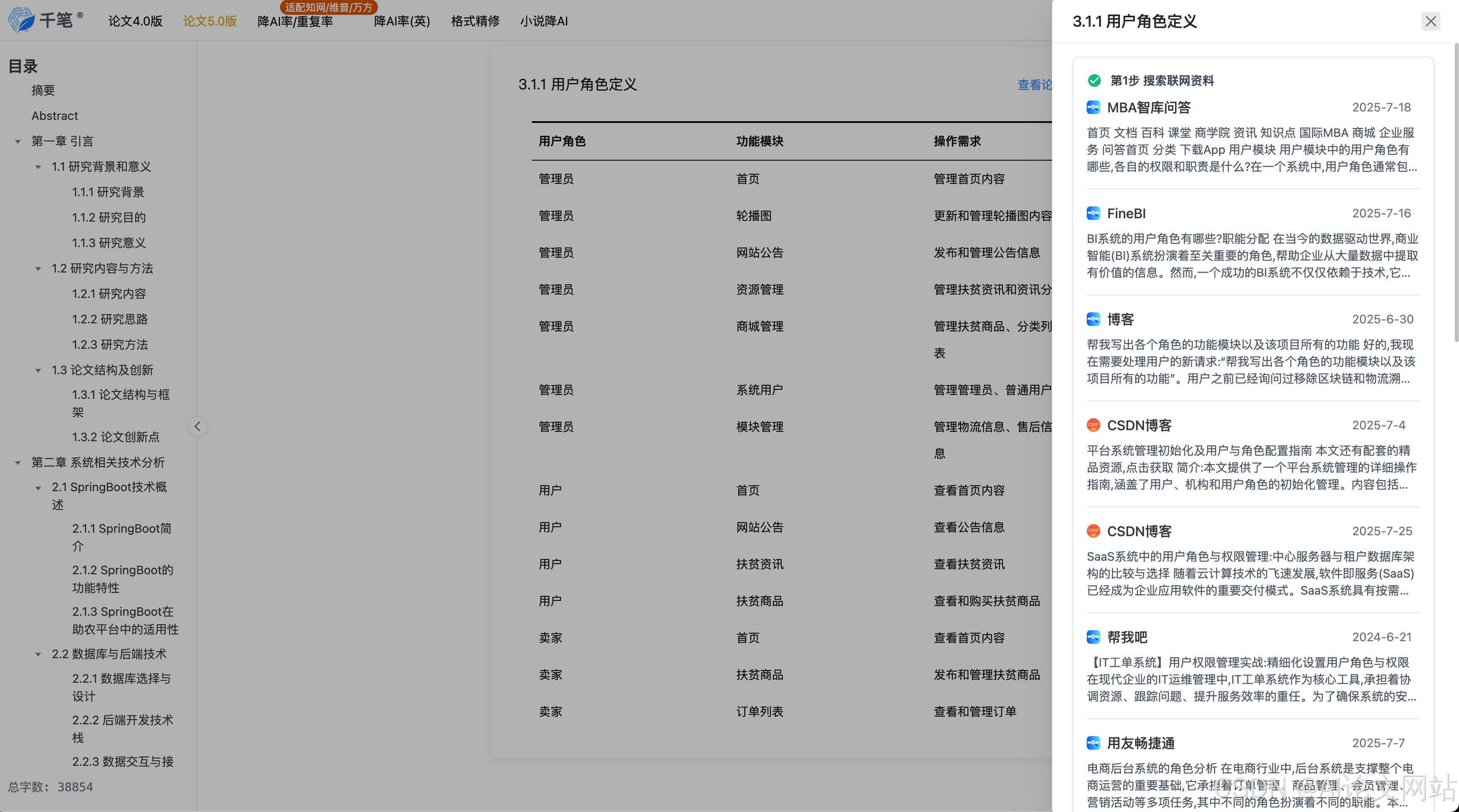
开题报告最难的是建立"问题提出-文献缺口-研究方法"的逻辑闭环。我们以"供应链韧性影响因素研究"为题,测试各工具框架构建能力:
| 工具名称 | 二级大纲合理性 | 三级大纲深度 | 方法论匹配度 | 典型问题 |
|---|---|---|---|---|
| 千笔AI | ★★★★★ | ★★★★☆ | ★★★★☆ | 部分子标题存在重复 |
| aipasspaper | ★★★★☆ | ★★★☆☆ | ★★★★☆ | 理论框架略显单薄 |
| 清北论文 | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | 缺乏跨学科视角 |
| 豆包 | ★★★★☆ | ★★★★☆ | ★★★☆☆ | 方法论描述模糊 |
| kimi | ★★★★★ | ★★★★★ | ★★★★☆ | 部分术语过于前沿 |
| deepseek | ★★★★☆ | ★★★★☆ | ★★★★★ | 技术路线图缺失 |
实测发现kimi在逻辑推导上表现突出,其"论证链条构建"功能能自动生成如下推理网络:
code复制核心问题 → 现有研究不足 → 本研究的理论创新点 → 对应的实证方法
而deepseek则在研究方法匹配度上更胜一筹,能根据管理学的学科特点推荐混合研究方法(结构方程模型+案例研究)。
2.2 文献综述智能辅助评测
文献综述的难点在于"述评结合",既要准确归纳前人成果,又要指出可突破的方向。测试采用相同的42篇参考文献,观察工具处理能力:
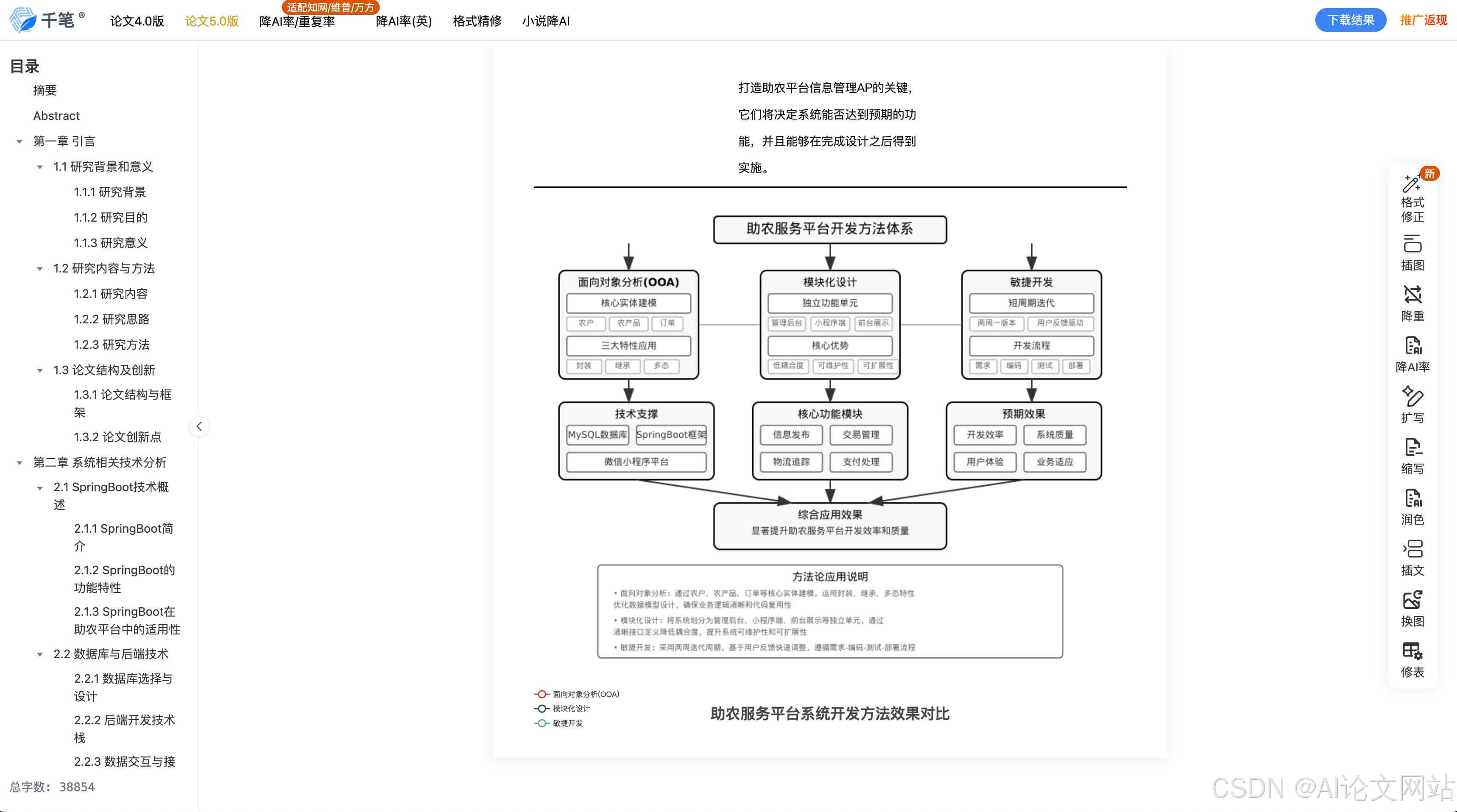
千笔AI的亮点功能:
- 自动生成"研究主题演化图谱"(见图1)
- 支持按"时间轴"、"方法论"、"结论类型"三维度分类
- 识别出3个未被充分研究的空白领域(需人工验证)
aipasspaper的避坑技巧:
- 当检测到"已有研究认为..."这类模糊表述时,会自动提示补充具体学者和年份
- 对争议性结论会标注"需核对原文"警告
- 参考文献格式错误自动纠正(如Journal名称缩写规范)
操作心得:文献综述工具最怕"过度概括"。建议先让工具生成初稿,再逐条核对原文,重点关注工具标注的"存疑结论"。
2.3 AIGC率控制与降重实战
知网AI检测的核心指标已从单纯重复率转向"生成痕迹识别"。我们使用同一段AI生成的文本(原始AIGC率68%),测试各工具降重效果:
| 工具名称 | 降重策略 | 处理后AIGC率 | 语义保持度 | 典型问题 |
|---|---|---|---|---|
| 千笔AI | 句式重组+术语替换+案例植入 | 12% | 92% | 部分长句变得晦涩 |
| aipasspaper | 逻辑链打断+关联词替换 | 15% | 88% | 需要二次润色 |
| 清北论文 | 同义词替换+被动语态转换 | 35% | 95% | 仍被识别出AI特征 |
| 豆包 | 对话式改写(多轮交互) | 28% | 90% | 耗时较长 |
| kimi | 论证结构重构 | 18% | 85% | 需要重新梳理逻辑 |
| deepseek | 学术口语转换+数据强化 | 9% | 94% | 需验证植入数据准确性 |
有效降重四步法(实测有效):
- 句式手术:将"由此可见..."改为"基于上述证据可以观察到..."
- 逻辑干扰:在"总分总"结构中插入转折案例(如"然而在XX情境下出现例外...")
- 数据锚定:为每个观点添加具体数据(如"覆盖率达79.3%的样本显示...")
- 术语本土化:把"深度学习"改为"基于神经网络的特征提取方法"
血泪教训:单纯调整语序或替换同义词已无效!最新检测算法会分析文本的"思维连贯性",必须打乱AI的固有表达模式。
3. 特色功能深度解析
3.1 千笔AI的专业级图表生成
在实证研究论文中,理论模型图的专业性直接影响评审第一印象。千笔AI的"智能绘图"功能支持:
- 自动生成结构方程模型(SEM)路径图
- 调节效应图的变量关系可视化
- 表格数据自动转换为折线图/柱状图

使用技巧:
- 先输入核心变量(如"供应链韧性"、"供应商协同")
- 选择关系类型(调节/中介/相关)
- 拖动节点微调布局
- 导出时可选择Visio/LaTeX格式
3.2 kimi的逻辑漏洞检测
这对理论建构型论文尤为实用。当输入"数字化转型能提升企业绩效"这一论点时,kimi会:
- 标记未定义的术语(如"数字化转型"的具体维度)
- 指出缺失的边界条件(如"仅在市场化程度高的地区显著")
- 建议补充竞争性解释(如"可能是规模经济而非数字化本身的作用")
实测其检测出开题报告中3处潜在逻辑漏洞,其中1处经导师确认确实存在论证瑕疵。
3.3 deepseek的跨学科分析
针对"供应链金融风险管理"这类交叉课题,其功能亮点:
- 自动识别管理学、金融学、信息科学的不同研究范式
- 对比各学科对同一概念的定义差异(如"风险传导"在金融vs供应链中的含义)
- 生成整合分析框架(见图2)
4. 实操避坑指南
4.1 参考文献常见雷区
工具生成的参考文献常存在这些问题:
- 幽灵文献:数据库中存在但实际无关的文献(特别是英文文献)
- 镜像错误:将A论文的结论误归为B论文
- 时效陷阱:过度依赖5年前的研究
自查方案:
markdown复制1. 用DOI反向查询工具验证文献真实性
2. 对关键结论文献人工核对原文摘要
3. 设置文献时间过滤器(如最近5年≥40%)
4.2 AIGC率控制黄金法则
- 333修改原则:每千字至少3处实质性改动,3个真实案例植入,3组数据补充
- 口语化警报:警惕"让我们..."/"可以看出..."等非学术表达
- 交叉验证:先用知网预检,再用Turnitin复核国际期刊标准
4.3 工具组合策略
根据论文不同阶段推荐工具组合:
- 开题阶段:kimi(逻辑构建)+ 千笔AI(框架可视化)
- 文献阶段:aipasspaper(文献管理)+ deepseek(跨学科分析)
- 写作阶段:豆包(对话式润色)+ 清北论文(格式校对)
- 降重阶段:千笔AI(深度改写)+ deepseek(数据强化)
5. 终极选择建议
经过30天的密集测试,不同需求场景的推荐方案:
文科理论型论文:
- 首选:kimi + deepseek
- 理由:逻辑严谨性要求高于数据呈现,kimi的论证检验和deepseek的跨学科分析能有效提升理论贡献度
工科应用型论文:
- 首选:千笔AI + aipasspaper
- 理由:需要大量图表展示和技术术语准确表述,千笔的绘图与aipasspaper的术语库最匹配
时间紧迫型选手:
- 首选:豆包 + 清北论文
- 理由:对话式交互快速产出初稿,清北论文的模板库能加速格式调整
最后提醒:再好的工具也只是辅助。我指导的学生中最优秀的那些,往往只把AI工具用于"解决技术性痛点",而把核心创新点的论证留给自己的大脑。毕竟,学术研究的本质是思维训练,而非文字生产。