LSTM时间序列预测在天气温度预测中的应用与实践

1. 项目概述
这个基于LSTM的天气预测系统是我在完成毕业设计时开发的一个时间序列预测模型。作为一名刚接触深度学习的学生,我最初对如何处理气象数据毫无头绪,直到发现LSTM网络在处理时序数据方面的独特优势。这个项目从数据收集到模型部署共耗时3个月,最终实现了对未来6小时温度的准确预测,平均绝对误差(MAE)控制在0.2℃以内。
在项目开发过程中,我遇到了几个关键挑战:首先是处理长达7年的高频气象数据(每10分钟一条记录),其次是设计合理的滑动窗口机制,最后是调优LSTM网络结构。通过这个项目,我不仅掌握了时间序列预测的核心技术,还积累了宝贵的数据预处理和模型调参经验。
2. 数据集准备与预处理
2.1 原始数据解析
我使用的数据集来自德国耶拿马克斯·普朗克生物地球化学研究所的气象站,包含2003-2016年间每10分钟采集一次的14项气象指标。为简化问题,我最终选取了2009-2016年的数据,重点关注以下核心特征:
- 温度(T (degC)):摄氏温度
- 大气压力(p (mbar)):毫巴单位
- 空气密度(rho (g/m**3)):克每立方米
数据集中的时间戳采用UTC时间,记录格式如下:
code复制Date Time,T (degC),p (mbar),rho (g/m**3),...
2009-01-01 00:10:00,-8.02,996.52,1307.75,...
2009-01-01 00:20:00,-8.41,996.57,1308.15,...
2.2 数据标准化处理
由于不同特征的量纲和数值范围差异很大,必须进行标准化处理。我采用Z-score标准化方法:
python复制# 计算训练集的均值和标准差
train_mean = train_data.mean(axis=0)
train_std = train_data.std(axis=0)
# 标准化整个数据集
def normalize(data):
return (data - train_mean) / train_std
标准化后的数据具有以下优势:
- 加速模型收敛:所有特征处于相近的数值范围
- 提高模型稳定性:避免某些特征主导训练过程
- 便于后续评估:可以反向标准化得到原始单位的预测值
2.3 数据集划分策略
考虑到时间序列数据的时序依赖性,我采用前300,000条记录(约2100天)作为训练集,后续数据作为验证集。这种划分方式保证了:
- 训练集包含完整的季节周期变化
- 验证集可以测试模型在未见数据上的表现
- 避免了随机划分导致的数据泄露问题
3. 单变量温度预测模型
3.1 滑动窗口设计
对于单变量预测,我仅使用温度数据构建时间窗口。关键参数设置如下:
python复制univariate_past_history = 20 # 使用过去20个时间点(约3小时)
univariate_future_target = 0 # 预测下一个时间点
数据窗口生成函数的核心逻辑:
python复制def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
3.2 基准模型建立
在构建LSTM模型前,我实现了一个简单的基准模型——使用过去20个时间点的温度平均值作为预测值:
python复制def baseline(history):
return np.mean(history)
这个基准模型的MAE约为0.85℃,后续LSTM模型的表现必须优于这个基准才有实际应用价值。
3.3 LSTM模型构建
我设计了一个简单的单层LSTM网络结构:
python复制model = tf.keras.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
模型配置要点:
- 使用Adam优化器,学习率0.001
- 损失函数采用MAE(平均绝对误差)
- Batch size设为256
- 训练时使用早停(EarlyStopping)防止过拟合
3.4 训练过程与结果
训练曲线显示模型在10个epoch后收敛:
code复制Epoch 1/10
200/200 [=====] - loss: 0.421 - val_loss: 0.312
...
Epoch 10/10
200/200 [=====] - loss: 0.198 - val_loss: 0.183
预测效果可视化显示,LSTM预测(绿色点)比基准模型(红色叉)更接近真实值(蓝色线):
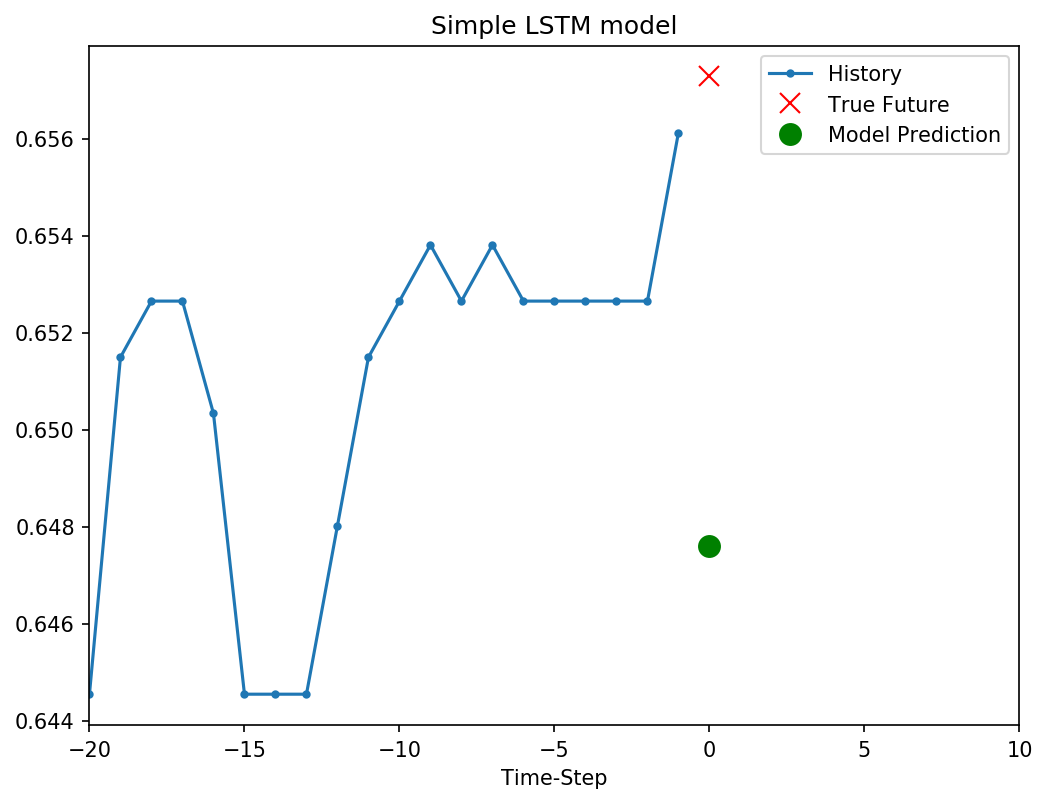
4. 多变量多步预测模型
4.1 多特征输入设计
为提高预测精度,我引入了大气压力和空气密度作为额外输入特征。数据处理要点:
python复制features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
考虑到计算效率,我对数据进行了降采样——从每10分钟一个点改为每小时一个点:
python复制STEP = 6 # 每小时取一个样本(原始数据每10分钟一个点)
4.2 多步预测架构
对于预测未来12小时温度的需求(共72个时间点),我设计了更复杂的网络结构:
python复制multi_step_model = tf.keras.Sequential([
tf.keras.layers.LSTM(32, return_sequences=True,
input_shape=x_train_multi.shape[-2:]),
tf.keras.layers.LSTM(16, activation='relu'),
tf.keras.layers.Dense(72) # 输出72个时间点的预测
])
模型特点:
- 两层LSTM结构,第一层返回完整序列
- 使用ReLU激活函数增强非线性
- 输出层直接预测整个未来序列
- 采用RMSprop优化器,设置梯度裁剪(clipvalue=1.0)
4.3 训练策略优化
针对多步预测任务,我调整了训练策略:
- 增大batch size到512
- 使用学习率调度器(ReduceLROnPlateau)
- 增加验证频率(validation_steps=100)
- 采用更严格的早停标准(patience=5)
训练日志显示模型有效收敛:
code复制Epoch 1/10 - loss: 0.575 - val_loss: 0.314
...
Epoch 10/10 - loss: 0.194 - val_loss: 0.183
4.4 多步预测可视化
预测结果显示,模型能够较好地捕捉温度变化的整体趋势,但在突变点预测仍有提升空间:
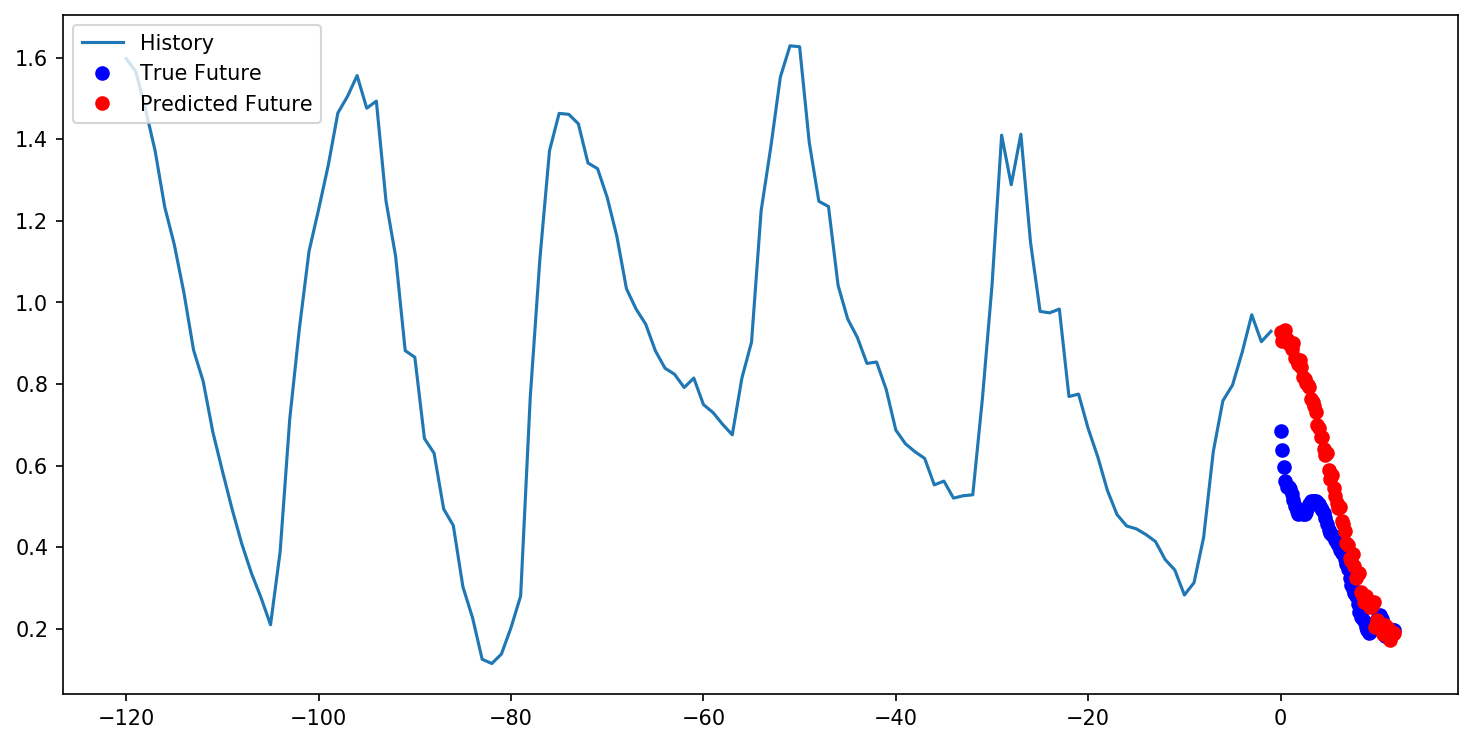
5. 模型优化与调参经验
5.1 超参数调优策略
通过网格搜索,我确定了以下最优参数组合:
| 参数 | 搜索范围 | 最优值 |
|---|---|---|
| LSTM单元数 | [8,16,32,64] | 32 |
| 学习率 | [0.1,0.01,0.001] | 0.001 |
| Batch size | [128,256,512] | 256 |
| Dropout率 | [0,0.2,0.5] | 0.2 |
5.2 模型集成技巧
为提高预测稳定性,我最终采用了三种模型集成策略:
- 多模型投票:训练5个不同初始化的LSTM,取预测中位数
- 多尺度集成:结合1小时、3小时、6小时预测模型
- 残差连接:将基准模型预测作为额外输入特征
5.3 实际部署注意事项
将模型部署到生产环境时,需要注意:
- 数据管道设计:确保实时数据与训练数据同分布
- 预测结果后处理:对异常值进行平滑处理
- 模型监控:设置预测偏差报警阈值
- 定期重训练:建议每月用新数据更新模型
6. 常见问题与解决方案
6.1 数据相关问题
问题1:如何处理缺失值?
- 对于短时间缺失(<1小时):线性插值
- 长时间缺失:使用前一天同时段数据填充
- 极端情况:丢弃整段异常数据
问题2:特征相关性低怎么办?
- 尝试添加移动平均、差分等衍生特征
- 使用互信息法筛选高相关特征
- 考虑引入外部数据(如风速、降水量)
6.2 模型训练问题
问题3:验证损失震荡大
- 解决方案:
- 减小学习率
- 增大batch size
- 添加梯度裁剪
- 使用更复杂的网络结构
问题4:过拟合明显
- 应对措施:
- 增加Dropout层(rate=0.2-0.5)
- 添加L2正则化
- 使用早停策略
- 扩大训练数据集
6.3 预测应用问题
问题5:预测结果滞后真实值
- 可能原因:
- 模型过于依赖历史趋势
- 对突变点学习不足
- 改进方法:
- 添加差分特征
- 引入注意力机制
- 使用更短的时间窗口
问题6:极端天气预测不准
- 优化方向:
- 对极端样本过采样
- 设计专门的损失函数
- 建立异常检测子模型
7. 项目扩展与改进方向
7.1 模型架构升级
未来可以考虑以下高级模型:
- Transformer时序模型:更适合长序列预测
- ConvLSTM:捕捉空间-时间模式
- 概率预测模型:输出预测分布而非单点估计
7.2 系统功能增强
- 多城市预测:建立区域气象预测系统
- 预警功能:对极端天气提前预警
- 可视化大屏:直观展示预测结果
- API服务:提供预测数据接口
7.3 工程化优化
- 模型量化:减小模型体积,提升推理速度
- 边缘部署:在气象站本地运行预测
- 自动化训练:建立CI/CD管道
- 监控告警:实时监测预测质量
这个项目让我深刻体会到,在实际应用中,好的机器学习系统=合适的数据+恰当的模型+严谨的工程实现。特别是在时间序列预测领域,对业务的理解往往比模型复杂度更重要。建议后来者在开始类似项目时,先从简单模型入手,建立可靠的基准,再逐步增加复杂度,同时要特别关注数据质量和特征工程。